We’ve been beating this topic to death, ever since the More was released and the @SpudGunner dude asked why not the More 3.
So @Volusiano, and several others opined that Oticon was crippling the More 1 by setting NNS Difficult to the default, and not the max, which it is capable of.
Oticon’s mantra (as @Volusiano alluded to it) was always the same: leave it alone, unless the client complains.
Well, I got curious, and called Oticon support, and asked that very question.
The reply was, durring 1st fit, most find the default value to be best.
In cases where the client expresses difficulty in focusing while in extreme environments, the value may be increased, but there is a caveat:
The person, or persons you’re focusing on will be clear, but some distortion may be apparent to the client of ambient sound, as the max value is more aggressive.
So, while we’re lead to believe the More will only apply the amount necessary, it will, under really difficult conditions, cause the kind of muffled, or distorted scenario ,much like @ubabopepton experienced.
Bottom line, it seems is if you want the best of both worlds, do as @Volusiano suggested in another thread, and create a program with NNS Difficult set to max.
That’s all, folks!
.
Thanks for the succinct summary of the issue, @flashb1024 !
I find some fallacy in Oticon’s answer that I’d like to point out here. Let’s take 2 scenarios:
Scenario 1: Max is 8 dB Sub scenario 1.a: Complex environment: let’s say -8 dB is applied, so speech is clear, ambient sound not distorted. Sub scenario 1.b: Very Complex environment: only -8 dB is applied because this is max → speech is not as clear as 1.a anymore because this is Very Complex env; ambient sound not distorted because it’s still only -8 dB.
Scenario 2: Max is 10 dB Sub scenario 2.a: Complex environment: More is smart enough to apply only -8 dB as needed → speech is clear like in 1.a, ambient sound not distorted like in 1.a because only -8 dB is applied as needed since More is smart. So 2.a has the same result as 1.a. Sub scenario 2.b: Very complex environment: speech would not have been as clear as 2.a had it not been for the -10 dB which clarifies speech further, so now speech is as clear as 2.a, ambient sound is distorted because this is a trade-off for using -10 dB.
In looking at scenario 1.a and 2.a, you get the same result, so we don’t need to do any deep dive into them.
But if you find yourself in Very Complex situation, which scenario would you have preferred? 1.b or 2.b? With 1.b, you may have less clear speech, but hey, your ambient sound is not distorted/muddied! With 2.b, you have clearer speech than in 1.b, at the expense of a more muddied ambient sound.
What is your priority? The clearer speech in Very Complex env.? Or the less distorted ambient sound at the expense of less clear speech? Obviously Oticon is advocating for the later (clearer ambient sound at expense of less clear speech in Very Complex env). I would personally have preferred the earlier (clearer speech at the expense of less clear ambient sound in Very Complex env).
Luckily, however, you can have both, though not in the same program. Just set 1 program with the priority for clearer ambient sounds (the Oticon’s recommended way), and another program with priority for clearer speech (at the expense of muddy ambient sound).
Another thing the Oticon answer to @flashb1024 did not make clear is whether that muddied/distorted ambient sound (when a higher max value is used) happens ONLY in very complex env., or whether it happens even in less complex env. as well. I sure hope it’s the earlier and not the later. And if it’s the earlier, then it’s really not a huge deal to go for the highest max available.
I’d agree with the analysis here, however I’d also like to throw in both the previous experience of the wearer AND their degree/shape of loss.
In my experience of fitting, the More strategy seems to work better with milder/sloping losses for people who weren’t heavily dependent on their fixed directional programs within the aids.
People with bigger losses, flat 70dB and above, who like flexing their fixed/dynamic directional patterns to hear better in background noise; don’t seem to ‘get’ the Mores.
You could probably argue that give enough time, given enough adaption and lots of twiddling, you’ll get the More eventually, but if you ‘need’ to hear the speech right in front of you in a messy sound field, it’s perhaps not the best choice. Now this might point to a degree of auditory deprivation on the part of the wearer, but they want bang for their buck up front because they ‘know’ what a new hearing aid should sound like.
I find the More1 aids wonderful for my hearing loss, The OPN1 aids helped and I found I loved hearing all around me and I could understand speech better than before. The OPNS1 aids improved on the OPN1 aids and speech was somewhat improved. The More1 aids have totally changed my attitude about my hearing loss, I have so much better speech understanding and love hearing the surround sound that I get even for speech. Sure I have some issues with some speech environments. And now if I have to have my aids off I feel like I am deaf. And if I go back and wear my OPNS1 aids I feel like I have gone backwards on my speech understanding.
@Volusiano: I understand that Oticon has led us to believe in their technical copy and , to a certain extent in their marketing copy - that More is intelligent enough to apply noise suppression incrementally, either smoothly, as on a continuum, or step-wise, as where there are “detents” at 0dB, 3dB, 6dB, 10dB, etc.
When I listen to the words (and read the transcripts of the fitting seminars), I get a different impression.
Here’s what’s said in one of Oticon’s Genie2 seminars:
"Genie 2 Fitting Focus Series: Customizing MoreSound
Intelligence Settings
Recorded February 19, 2021
Presenter: Amanda Szarythe, AuD
However, it does give you the option to increase noise reduction for difficult environments when a patient is in difficult listening environments often and reporting they wish you could take away a little more of the background noise. Here, it is very important if a patient is struggling in noise to determine if the background noise is overwhelming for them or if they are having trouble hearing voices. An example of when you may increase the noise reduction is a patient that regularly goes to the same restaurant every Friday night and is reporting the background noise is overwhelming."
After listening to this and other seminars, I come away with the feeling that the application of NSS by the DNN is a binary proposition, and the chosen value is an absolute value cap.
So, I’m not sure that we can assume any super sensitive, incremental brake pedal for noise. But there’s nothing I can hang my hat on in their vague text.
Sorry, Jay … what query? The only query I have is “does or doesn’t More1 apply NSS incrementally, or is it an “on/off” proposition with an adjustable cap value?”
I don’t see the answer to that in the OP. (I’m beginning to wonder whether or not the "rebalancing of the soundscape " that the DNN performs isn’t, in its own right, a subtler and more discriminant form of noise suppression. Adjusting the max/min values of the secondary Neural Noise Suppression may introduce the distortion into what the DNN is doing, blurring the crisp edges of the sounds, and making everything seem muffled. But there’s no information on that that I’m able to find.)
Yes! Great point (and I understand it), but what if it were the DNN trying to manage the incremental part, but perhaps being interfered with somehow by NNS? I mean, if MoreSound Intelligence and the DNN were doing a flawless job, why would one need Neural Noise Suppression, anyway? There must be some sort of handoff, or synergy, the way I cipher it.)
[And I apologize if some of my statements are dumb, but I don’t have anything close to the technical knowledge you guys possess.]
Or Unitron-y? I believe my old Unitron North Moxi Fit 800 tried to do the automatic program selection thing (badly) , and the experience was horribly frustrating.
My understanding is that the Neural Noise Suppression is an integral part of the DNN, not a separate module. That’s why they call it “Neural” Noise Suppression in the More, and not just a separate “Noise Removal” module like they did with the OPN S.
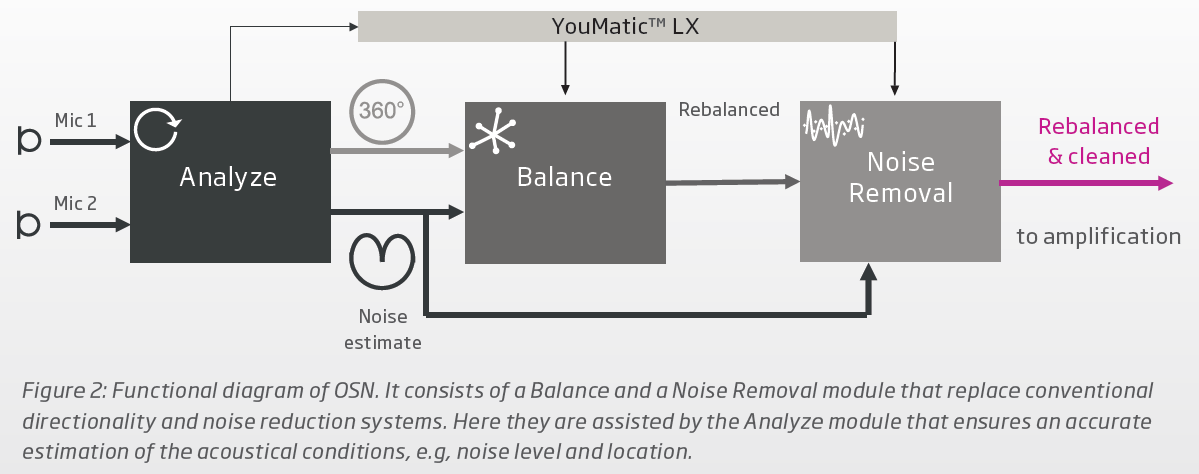
The Noise Removal module in the OPN (after the MVDR beam forming attenuation of well placed noise sources in the Balance module before it) removes the “diffused” noise by subtracting the Noise Model of sounds in the back and sides from the front sound scene. So that’s “real” noise reduction.
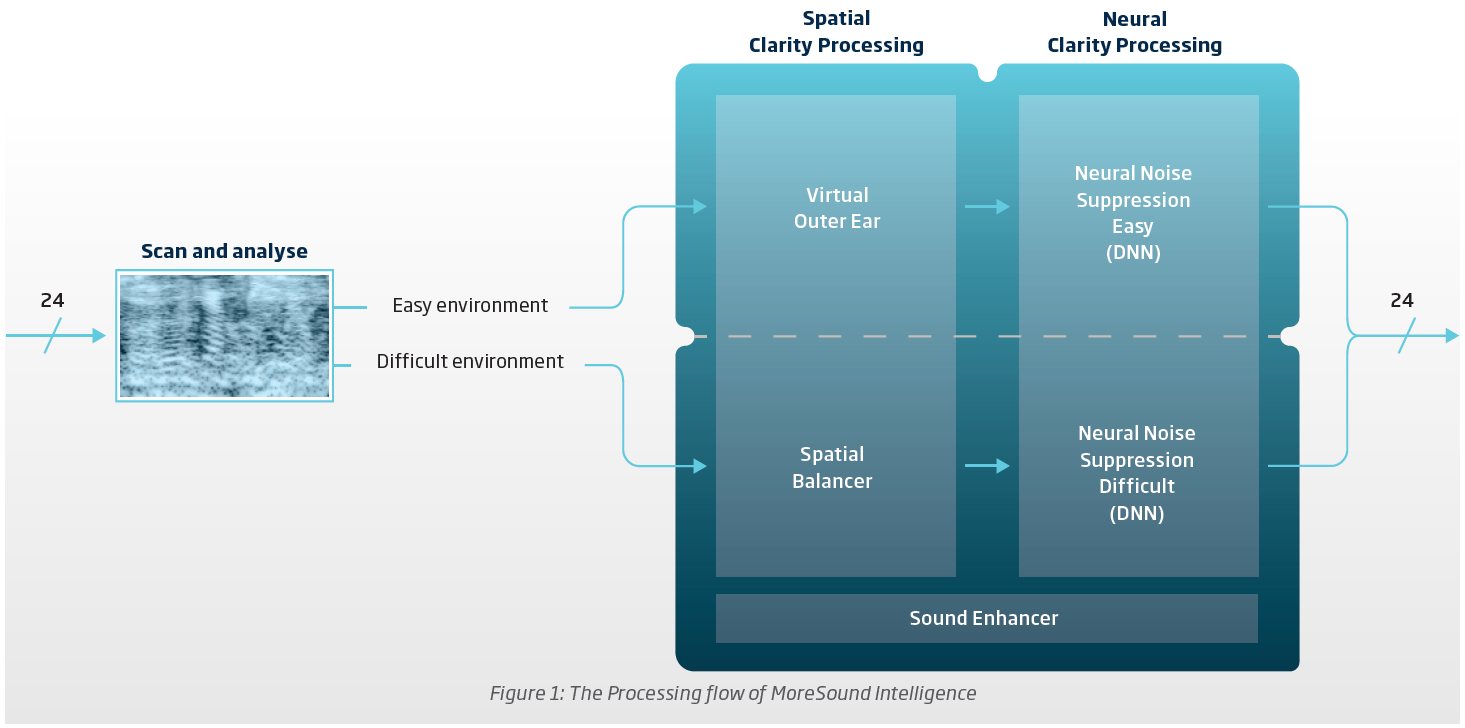
In the More however, although it has the MVDR beam forming attenuation of well placed noise sources in its Spatial Balancer module, just like the OPN’s Balance module, it does not use a Noise Removal module a la OPN. Instead, the DNN replaces it, and part of the DNN’s functionality is to do Neural Noise Suppression. So the More doesn’t rely on the previous noise removal technique that the OPN uses. It actually “suppresses” the “noise” simply by rebalancing the discrete sound components it has broken up inside the DNN, suppressing the non-speech sounds to lower volume levels, and actuating volume of the speech sounds to higher levels.
Because the DNN already has been trained to know how to accurately balance every sound scene, it is a smooth incremental process inside the DNN simply by default. The Neural Noise Suppression max value assigned by the user in Genie 2 puts a cap on the level of aggressiveness this “rebalancing” should be. It’s probably part of some assignable boundary conditions of certain weight and bias values for certain neural nodes inside the DNN.
@Volusiano: That’s a great explanation that even I can understand. Thanks again for taking the time to educate us, V. (with no offense intended to the other knowledgeable members who do the same.)
My interpretation of what they’re saying is this → (I’m going to try to rephrase it in my own way):
If a patient complains to you about being in a noisy place, you gotta ask them for clarification:
Is the noise just too much for you but you’re still hearing voices OK, except that you don’t like the extra noise?
Or is the noise way too much that it’s actually starting to overwhelm and actually impacting your ability to hear and understand the voices as well?
If the patient says the answer is 1 → don’t increase the max Neural Noise Suppression because they can still understand voices OK, so now if you give them crappy/muddied/distorted ambient sounds, they’re still not going to be happy anyway. Just make them live with it and tell them if they can hear voices OK still, then leave it alone and eventually their brain hearing will adapt and learn to live with the noise and tune it out.
But if the patient says the answer is 2 → then you better do something about it and max out this max Neural Noise Suppression value so the patient can understand the voices in these places. That’s the ultimate priority and they’ll be happy enough to understand the voices that they don’t mind if the ambient sounds are muddier. And if they complain, remind them that they should be happy to be able to hear the voices with your new adjustment, and stop complaining about muddied ambient sounds because the world is not perfect!!!
Now back to my own (Volusiano’s) commentary: if the patient doesn’t know better to complain to the HCP right away, or if the patient doesn’t or hasn’t encounter such a very complex environment to even realize that it may be an issue, the max value is kept at a “lesser” (I prefer to call it handicapped) value by the HCP at Oticon’s recommendation. Then the few times the patient gets into that very complex environment situation, their More 1 is handicapped by a lesser value and cannot perform as well as it should be able to on voices, all just for the sake of Oticon not wanting to get a black eye on having muddied ambient sounds at the expense of the patient not even knowing that they actually have a choice to choose to understand voices better or to hear ambient sounds better in the worst case sound scenario.
This hearing aid is doing less than you guys think. Keep in mind that the ‘deep neural network’ isn’t doing anything at all in the hearing aid, it was simply used to train the hearing aid’s automatic features on how to correctly categorize sound. The More still uses all the pre-existing Oticon noise reduction strategies.
Sounds like the Oticon More aids are directed towards the mass. Like other hearing aid manufacturers, it is all about the numbers and simple fittings.
Hate to be a drag or negative but this is where the money is.
You could almost separate this forum into two groups. It’s all about the hearing loss. The money is in the majority.
I really don’t care how they are doing it, all I know is that they are working wonders for my hearing loss. I haven’t heard this good since I can’t even remember when. I made my living in technology and still don’t care as long as it works. Now back when I had o fix the stuff the I cared about what made them tick. Now who really cares as long as it works.
Do you have some inside information on this you can share, @Neville?
The Balance module in the OPN and the Spatial Balancer module in the More are indeed the same thing that does the MDVR beam forming noise attenuation. That part was made pretty clear between the 2 whitepapers.
However, there’s no evidence that the Noise Removal module in the OPN is being used in the More, at least based on the 2 whitepapers. The Neural Noise Suppression in the More IS the DNN (see screenshot 1 below), while the Noise Removal module in the OPN is before any Oticon DNN exists, and it’s not shown or mentioned at all in the More whitepaper(see screenshot 2 below). These 2 noise reduction modules/strategies are not the same at all as far as I can tell.
But all we have for information are the 2 whitepapers. Maybe as part of the HCP network, @Neville is privy to more non-public information that we don’t have. We just don’t know what Oticon does with its DNN result. They never say directly that they use it to categorize sounds in their whitepaper. But they definitely say that they use the DNN to rebalance the sound scene. We can only infer from the limited information they release as to what they do with the DNN.
But whether they use it only to categorize sounds like @Neville said and drive the original OPN Noise Removal module to remove noise, or whether they use it to do neural noise suppression by rebalancing the discrete sound components by reducing non-speech sounds’ volumes and increase speech sounds’ volume like I assume they do, it actually doesn’t matter in terms of their implementation details, which we don’t know for sure anyway.
The bottom line is that I still think that their noise removal/suppression is continuously incremental (like with the OPN), and not binary like the impression @SpudGunner had after reading the Audiology online comments.