Yes, Rick, you do seem to be habitually negative towards anything Oticon. Nothing new be learned here, folks. ![]()
I still have a lot to learn about hearing aids, and I spend quite a bit of time reading on it, but six months into it, I’m still wondering what an unbalanced sound scene is. What’s out of balance with what? How would a hearing-compromised person determine the balance was out of whack in the first place?
As @Volusiano has stated on many occasions in the recent past :
I rather suspect that Neville may be closer to the truth than we’d like, that is: Mores operate the same way OpnSs do, pretty much, except the noise suppression algorithms have been defined heuristically, and not deterministically.
This doesn’t mean, however, that the heuristic methods used by the DNN to effect noise suppression in Mores are inferior. As one who is greatly satisfied with the performance of my More1s, I can say that they seem to do a great job of treating my hearing loss.
[I wish I had a valid point of comparison against which to compare the performance of my Mores, as does Chuck (@cvkemp) , but I don’t, preventing me from speaking with greater authority.]
Too bad we couldn’t get @Volusiano into a pair for a month!
This is incorrect. My thoughts about Oticon are they are really nice aids as well as other hearing aid brands.
Off topic and off color posts I am negative about.
My apologies for being off topic.
2 Likes
I have never posted an off-colour post, and I’m not about to let you get away with accusing me of it in the open Forum. Get a mod to contact about the off-colour post you allege, and I will gladly address it - but not here.
1 Like
New users/milder losses seem happiest with them.
Existing users with bigger losses and longer (non-Oticon) experience; not so much.
@Um_bongo: If I may trouble you - how would you characterize my loss?
Ski-slope, mild to severe.
Awkward AF to fit. That new Phonak receiver might be great for you though.
I just got More1s in April, and I love them. They’ve given me a lot better hearing than my previous Unitron North Moxi Fit 800s.
Thank you @Um_bongo
1 Like
My understanding is that during the training phase, a recorded sound scene (out of the 12 million) is fed into the DNN. Of course Oticon never said exactly what they do inside the DNN, but they do infer to being able to manipulate the various discrete sound components inside the sound scene (ex. they mentioned adjusting the sound made by the seagull w.r.t. other sounds in the sound scene). So I think a safe assumption is that their DNN breaks down the sounds in that sound scene into discrete sound components, like the sound of the seagull, the sound of voices, the sound of the tuba playing nearby, etc). Neville said all the DNN does is to “categorize” sounds correctly. I don’t know what that means, but it seems like it’s consistent with “sorting” or breaking down the sound scene into various discrete sound components as well.
Now come the “rebalancing” part that you’re wondering about, Jim. After the DNN has broken down the sound scene into various discrete sound components, it has to rebuild it before it can deliver the whole sound scene again at the output for the patient to hear. If there’s no manipulation needed (say, because it’s for a normal person), then ideally this “rebuilt output” needs to sound exactly like what was fed to the DNN’s input in order to retain the accuracy of not just the sound component’s integrity, but the volume of that sound component w.r.t. the volumes of all other sound components has to be recreated accurately, too. This is the initial rebalancing (for DNN training purposes) we’re talking about, which is simply just rebuilding the broken down sound components to duplicate exactly the original sound scene again. An analogy is to take a piece of puzzle apart, then rebuild it and put it back together again exactly the same way.
In order to determine how well the DNN has been able to rebalance (or recreate) the original sound scene, the DNN’s recreated/rebalanced sound scene (its output) is compared against the reference sound scene captured (and fed to the input) and the differences (inaccuracies) recorded. These differences get fed back into the DNN and weights and biases of the neural nodes get mathematically tweaked to minimize these differences. Of course minimizing doesn’t always mean that they can make the differences go to zero. But as long as they can make the differences become the smallest value possible, then they’ve achieved their goal for that round. Then they do the same for the next sound scene again. After 12 million iterations, they should have been able to train the DNN to be able to take in any real live sound scene, break it down into discrete sound components, then “rebalance” or “recreate” or “rebuild” that sound scene to sound almost exactly the same as what was fed into the DNN’s input.
The obvious question then is what’s the point of doing this? You can just use a simple amplifier to recreate the input with an exact copy at the output just the same. The difference is that the amplifier just makes a copy and is not able to break down the sound scene into discrete components. Meanwhile, the DNN can break down the sound scene into discrete components so that it can manipulate it via further independent signal processing of the individual components. For example, Oticon can put rules of thumbs into the DNN to say that for voice components, increase their volumes by X%. For droning/mechanical kind of noises, decrease them by Y%, for other noises that are not mechanical droning sounds, preserve them at their original volumes as to preserve the open paradigm, etc. Then the user’s inputs via various parameters inside Genie can affect this “rebalancing” further to match the user’s personal taste even more.
The original “rebalancing” during the training of the DNN is simply to recreate the sound scene’s balance as accurately as possible. The new “rebalancing” based on the user’s inputs and preferences as captured via Genie 2 is no longer the same as the original rebalancing anymore, because by then the goal is not to rebalance the output to match the input, but to rebalance the output to let the user hear things better the way THEY want to hear it.
1 Like
Thanks again, @Volusiano: this clarifies it for me exactly to the point. (I think I’d have understood better if Oticon had called what they’re doing a “remix” - just because the terminology is more familiar to me.)
1 Like
I think “remix” is a GREAT word to describe it. It’s also a great analogy as well for musically minded folks!
1 Like
Yes, that makes complete sense, since people using other mfg’s are probably somewhat overwhelmed by Oticon’s approach.
Longer non-Oticon experience is defintely the key.
For me, after 3months of the Phonak Marvel, I was literally begging my audi to get me back into the Oticon realm.
It’s all about expectations, and to some degree customer education by the fitter.
2 Likes
Hey @flashb1024
@JeremyDC asked me in the other thread by cvkemp that was closed all the questions which I answered, but like you pointed out, maybe it’d probably belong better in this thread. I don’t know why he asked the questions in the other thread, but he probably didn’t know about this thread until I pointed it out to him.
Anyway, if it’s OK with you, maybe we can bring the conversation of to this thread to continue its discussion, which is probably more appropriate anyway.
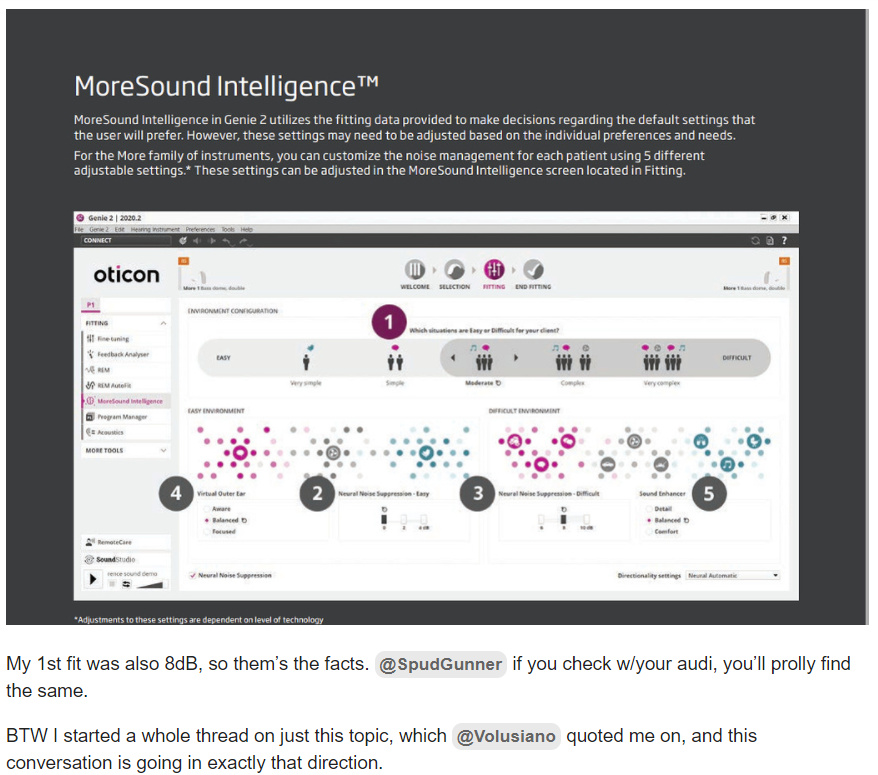
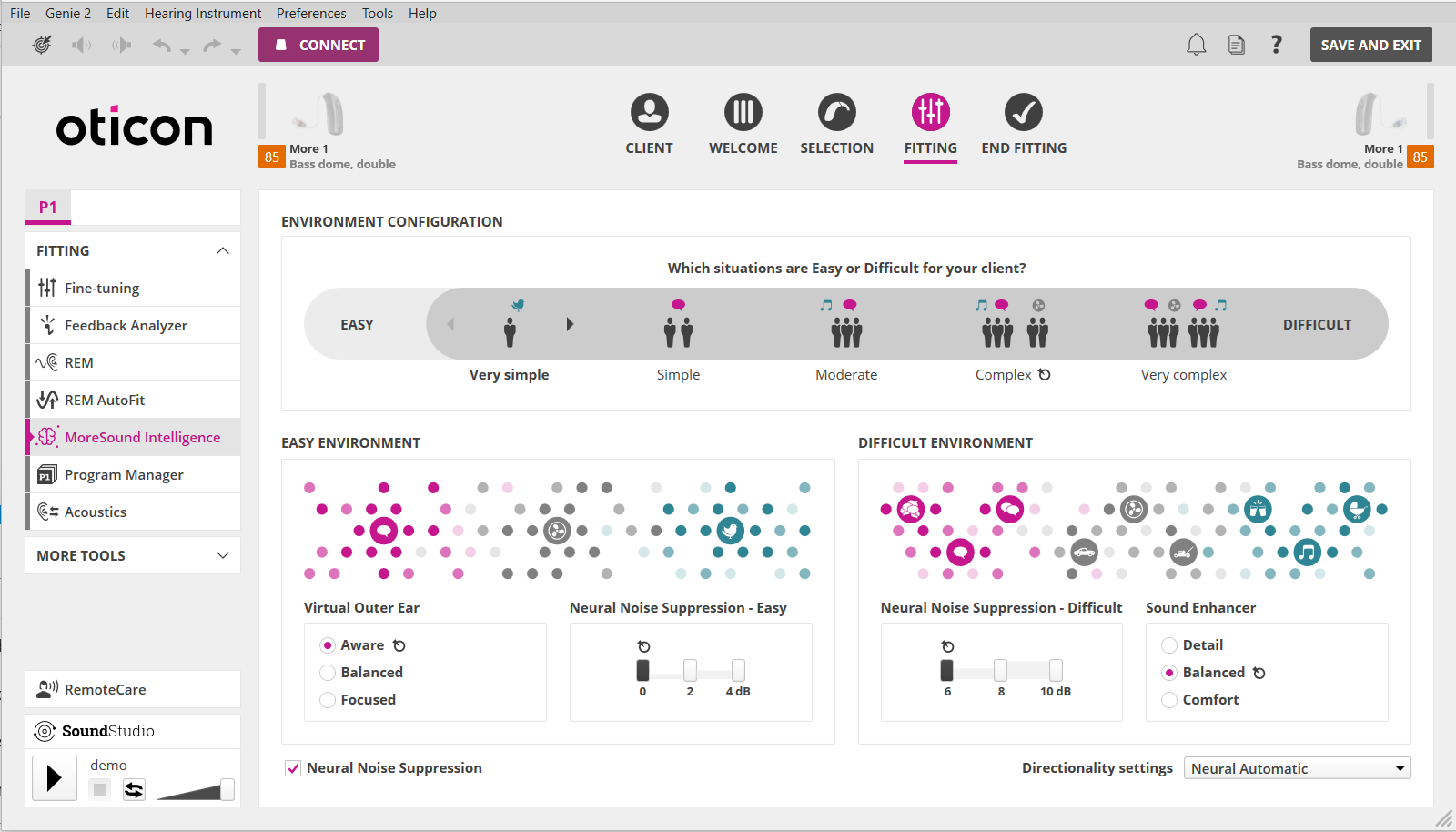
Regarding the default for NNS in Difficult, I was not trying to misdirect anything. In my screenshot that I showed, obviously Genie 2 decided that for MY situation, with MY hearing loss and MY personalization, that the default should be at 6 dB and not 8 dB as seen in the screenshot. Also note that even if I made the Difficult configuration to include everything, including the Very Simple situation as seen in my screenshot, it’d still default for me at 6 dB.
If your default is at 8 dB, that just goes to show that it can be different between people based on their personal situation on the hearing loss and personalization.
Below is the personal screenshot that I have for my hearing loss and personalization, showing that Genie 2 picked MY default to be 6 dB.
1 Like
@JeremyDC I don’t know if this is the appropriate thread to discuss the Virtual Outer Ear topic or not, but since the VOE is a module that drives into the NNS for Easy Environment, I hope that @flashb1024 is OK with me posting it here, since it’s really not worth creating a whole other thread to discuss this rather minor item.
But @flashb1024, if you prefer that we move this discussion to another thread, please let me know and I’ll remove it and post it in a new thread.
Just to recap, I was of the impression that VOE settings is not a big deal to just have Balanced only, and @JeremyDC shared his opinion that going from Balanced to Aware seems to make a significant difference for the better for him.
I think that this is good and maybe in hindsight after you already have the More 1 and find that Aware is worth paying for the More 1, then that’s great. But I just want to clarify that it doesn’t really do much noise management per se, it only tries to model the real ear pinna to simulate 3 different outer ear pinna types using the Directivity Index (DI) measurements, that’s all.
Below is some verbage on it. You can see that it says Balanced is designed to create the best ratio between audibility of all sounds while being able to focus on speech from the front. So while you have a personal preference for Aware, in real life, that’s still a personal preference. So that’s why I think that Balanced, in the context of having to sacrifice some choices to pay less for a lower tier model like the More 2 or 3, is still OK.
Because the VOE is only activated if the HA deems that you’re in an Easy environment (depending on your Environmental configuration selection), if you put aside the personal preference, I don’t think Balanced is such a bad choice that would hamper the ability to hear more around you or the ability to focus in front. It’s a good compromise to have because in general, people should not have issue hearing surrounding sounds or speech in an Easy environment in the first place. And if they do (especially for speech), the mild NNR settings for Easy environment should take care of it.

FWIW, I’ve worn both More1s, and also More3s. I spend most of my days in a quiet environment, and didn’t notice a difference in the performance of the two tiers - except when I’m playing my music - although there’s lots of differences on paper.
Thanks for keeping the discussion going. Perhaps I should have started a new topic on this subject. I will keep going here, but can move the discussion to a new topic if people would prefer I do so.
As I said, the Aware setting made a difference for me, but I am still trying to get the aids to deal with the following situation: One or two people who are quite understandable in a noisy environment (washing machine and refrigerator noises) who then move to another room around the corner and keep talking to me. The noise where I am located stays the same, but the voices lose volume since they are further away and most importantly, lose clarity and become for lack of a better word, mush and are no longer understandable. Shouldn’t the aids lower the noise in my immediate environment, so I can hear the voices I am trying to listen to? Is this still considered an “easy environment” and so, if no noise reduction is dialed in, that they won’t provide it, or does this become a more complex environment when they move away and the aids should try to reduce the noise, so I can hear the conversation? What adjustments should be tried to make this situation better? (I am meeting with my audiologist this morning and will be asking the same question.) Is this a neural noise reduction setting issue or something else? Am I expecting too much of the aids in this setting? Is this caused in part by my trying to hear too much sound with the Aware setting? Appreciate your thoughts.
@JeremyDC: Oticon never really defines “Quiet”, however (and everything is relative), I wouldn’t classify the environment you’re describing as “Noisy”. I guess the important question is what the HAs class it as.
I also don’t know what Oticon’s engineers contemplated as a strategy for dealing with stationary noise sources when the speech sources are moving away. Sounds pretty challenging to me, and one in which there would have to be some pretty aggressive compression and noise reduction going on at the same time.
(Perhaps @Volusiano will be able to shed some light on the capabilities of your devices when he sees his tag …)
I don’t know whether your expectations are realistic or not - IMO, that’s something that always needs to be discussed with your audiologist. Hopefully, they are well-informed enough to answer that question, or wise enough to call Oticon for support, if they don’t know the answer off hand.
YOU (through your HCP) get to decide what is Easy and what is Difficult Environment. The screenshot below shows how mine is set by default. Based on my hearing loss and my personalization settings, Genie 2 choose my Difficult Environment to include Complex and Very Complex situations (the dark gray area on the right), and Easy Environment became the other 3 (Very Simple, Simple and Moderate → the lighter gray area on the left). You can have your HCP change this setting for you.
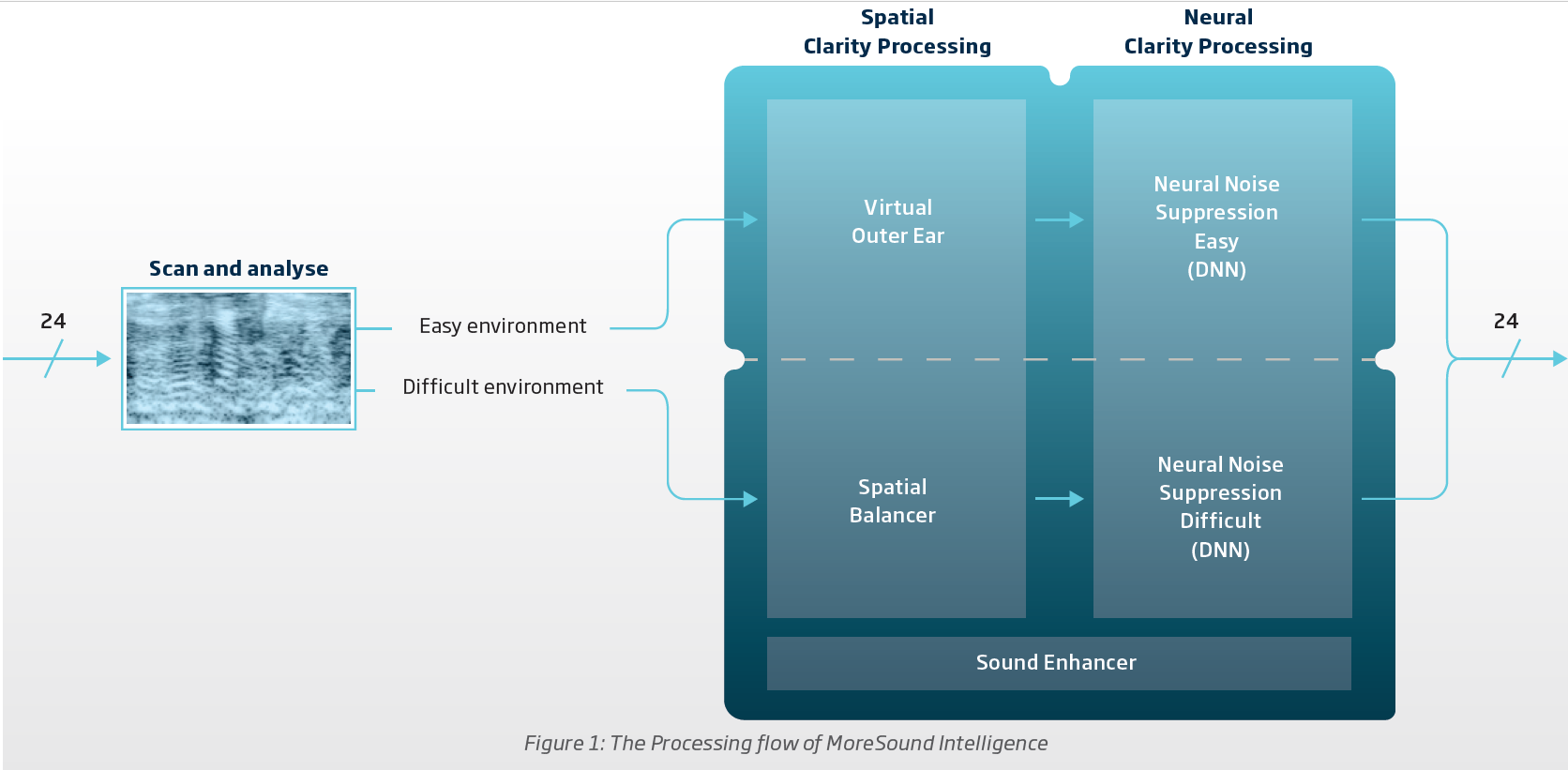
The reason for defining this to what you want is so that the More knows how to route the signal after the Scan & Analyze module to one of those 2 environments (Easy & Difficult) in order to process them in accordance to the flow in the second screenshot below. What you classify as Easy gets routed to the Virtual Outer Ear before it goes into the NNS DNN for Easy. What you classify as Difficult gets routed to the Spatial Balancer (MVDR beam former to remove well placed noise sources) before going into the NNS DNN for Difficult.
The icons for Very Simple, Simple, Moderate, Complex and Very Complex as seen in the first screenshot are descriptive of how the Scan & Analyze module will classify the situation. It looks like Very Simple is you alone hearing things by yourself. Simple is when you have a one on one conversation with somebody. Moderate is where you have more than 2 people talking together with some music going on. Complex is multiple groups of people talking with maybe music and noise (fan and/or engine/appliance sounds) going on. Very Complex is multiple larger groups with multiple conversations going on, on top of music and noise.
Notice that if what you hear gets routed through the Difficult Environment flow, the Virtual Outer Ear setting is no longer applicable/active to what you hear. VOE is only applied if the signal is classified (ultimately by you) as Easy Environment.
Now for the particular situation you mentioned, with appliance noises going on and 1 or 2 people talking with you then they move to another room around the corner, then speech may lose enough volume and becomes more like babble. It’s unclear how the More DNN is designed to treat babbles, whether still as speech of some sort, or now as noise.
I assume that with the appliance noises going on, it’s a Moderate situation. As to your question whether or not this is still considered an Easy environment depends on how you classify the Moderate situation as in the Environment Configuration in the screenshot below. If you classify it as Easy, then it’s still routing through the Easy path → the VOE, then the NNS DNN for Easy. And if your default NNS for Easy is set at 0 dB and you leave it that way, it will not try to do any kind of NNS for you and give some priority to speech. It’s possible that it longer detects speech because the conversation in the other room around the corner may have become babbles, unless those 1 or 2 folks talk really loud and their voices still carry over to where you’re at.
What can you do in that situation with the settings to improve it? Well, not much if the speech has gotten weak enough to become babble. If you had set the Moderate situation to be part of the Simple Configuration, then if VOE is set to Aware, that should help you hear the voices in the other room better if you can pick them out amongst the appliance noises (that’s up to your brain hearing now). And if you set the default NNS in Simple Environment to at least 2 or even 4 dB, that should help rebalance to attenuate the noisy appliances and gives some priority to speech (if the voices is still loud enough for the DNN to treat them as speech).
A better approach would be to configure the Moderate situation as part of the Difficult Configuration This way, the Spatial Balance will try to attenuate the appliance noises more aggressively (the VOE does not do this), and the NNS in the DNN for Difficult can apply a higher max NNS value of 6 dB or more to give better priority to the speech compared to only the 4 dB NNS in the Simple flow path.
BUT, I can only recommend the most optimal settings for that situation, but it’s no guarantee that it’ll help. There’s still only so much the aids can do if the voices in the other room are not really intelligible enough to be detected as speech. If the DNN classifies the weak voices in the other room as babbles/noise and not as speech, then the DNN may not give it the priority it needs anyway.
I’d be grateful enough to be able to hear and understand conversation in the same room or nearby in an open space, but expecting the aids to be able to pick up conversation in a next room around the corner may be too much to ask. Heck, I don’t know if it’s easy for normal hearing people to pick it up either.

1 Like
So, that is exactly what my audiologist told me!
I checked how my aids were set up and this morning had her set up a special program with moderate as the default, and the noise reduction module for Simple environment set at 2. Did that prior to reading your suggestion which mirrored what she did, which is kinda cool. She also added some sibilance for improved intelligibility for Program One and for the new program. I will be checking back with her in two weeks.
That was the whole point in starting this thread, so yeah!