Your audi is completely wrong (and demonstrated a lack of basic understanding of how it works, even though she made it sound like she really knows what she’s talking about by overriding your request) that the Detail setting on the Sound Enhancer would eliminate a lot of the noise reduction. Why? Because the Neural Noise Suppression inside the DNN is already DONE before the signal goes through the Sound Enhancer. So the relationship between the noise and the speech (in terms of the Signal to Noise Ratio) is already established before it goes through the Sound Enhancer, and this SNR remains the same and does not get changed by the Sound Enhancer. Therefore, the noise reduction doesn’t get “eliminated” like your audi alluded to.
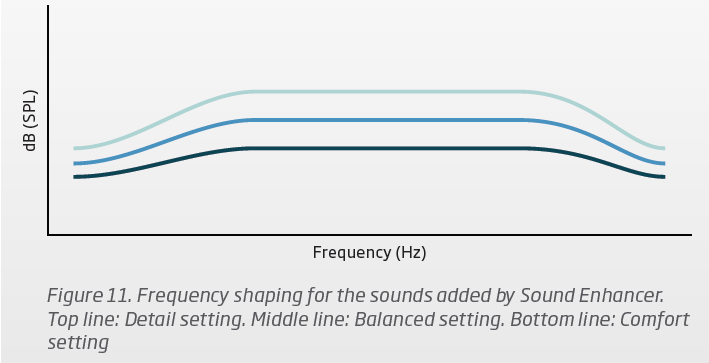
The Sound Enhancer is simply nothing but a bandpass filter (see screenshot below) that provides more attenuation on the low and high frequency ends, with more gain in the mid frequency. The Detail setting (the top curve) gives you more gain compared to the Balanced (middle curve) and Comfort (bottom curve).
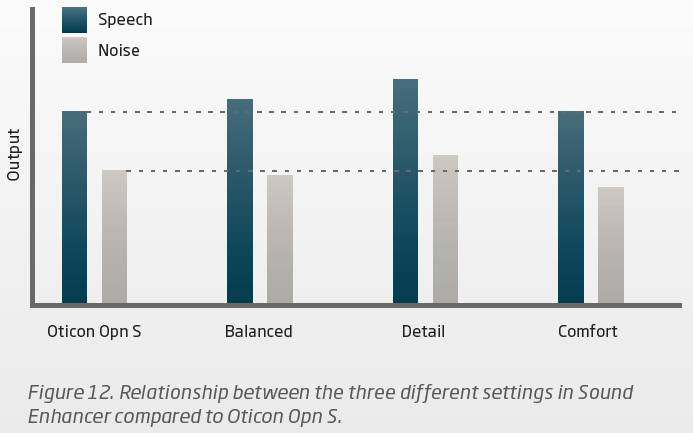
If you look at the second screenshot below, you can see the effect of the Sound Enhancer in the 3 settings, and also relative to the SNR in the OPN S. As you can see, the More provides better SNR in its Neural Noise Suppression compared to the SNR achieved by the OPN S (max noise reduction in OPN S 1 is -9 dB while max noise reduction in More 1 is -10 dB by the way). This is obvious because you can see that the speech output has more gain in the More (Balanced setting) compared to the OPN S, and the noise in the More is not as loud (in Balanced setting) compared to the OPN S.
Now all the Sound Enhancer does is boost BOTH the speech and noise up a little by the same amount of gain, as can be seen in the Detail graph, and reduce both the speech and noise by the same amount of gain in the Comfort graph compared to the Balanced graph. So NO noise reduction gets “eliminated” like your audi said. The noise reduction is already done up front before it goes to the Sound Enhancer phase, and the SNR of the noise reduction remains the same ratio regardless of the Sound Enhancer setting. All the Sound Enhancer does is to either boost up both speech and noise signals in Detail, or lower down both speech and noise signal in Comfort.
The purpose of the Sound Enhancer is to allow for individualized customization because after the Neural Noise Suppression does its job, some folks may feel like the Neural Noise Suppression is too aggressive and takes away too much noise (meaning environmental sounds that they may want to be aware of to hear more of), while some folks may feel like the Neural Noise Suppression is not aggressive enough as they’d like it too, and there’s still too much noise. So with the Sound Enhancer, folks who feel like it takes away too much noise can choose Detail to increase the output level of the noise so they can hear more of it (and speech gets boosted further, which for the most part should be OK with the user). For folks who feel like there’s still too much noise, then the Comfort setting will help suppress the gain of the noise further for better comfort, while still maintaining the speech to noise SNR to the same level as before.
Below in the third screenshot is some verbage about the Sound Enhancer in the Oticon whitepaper that basically says what I just said above.

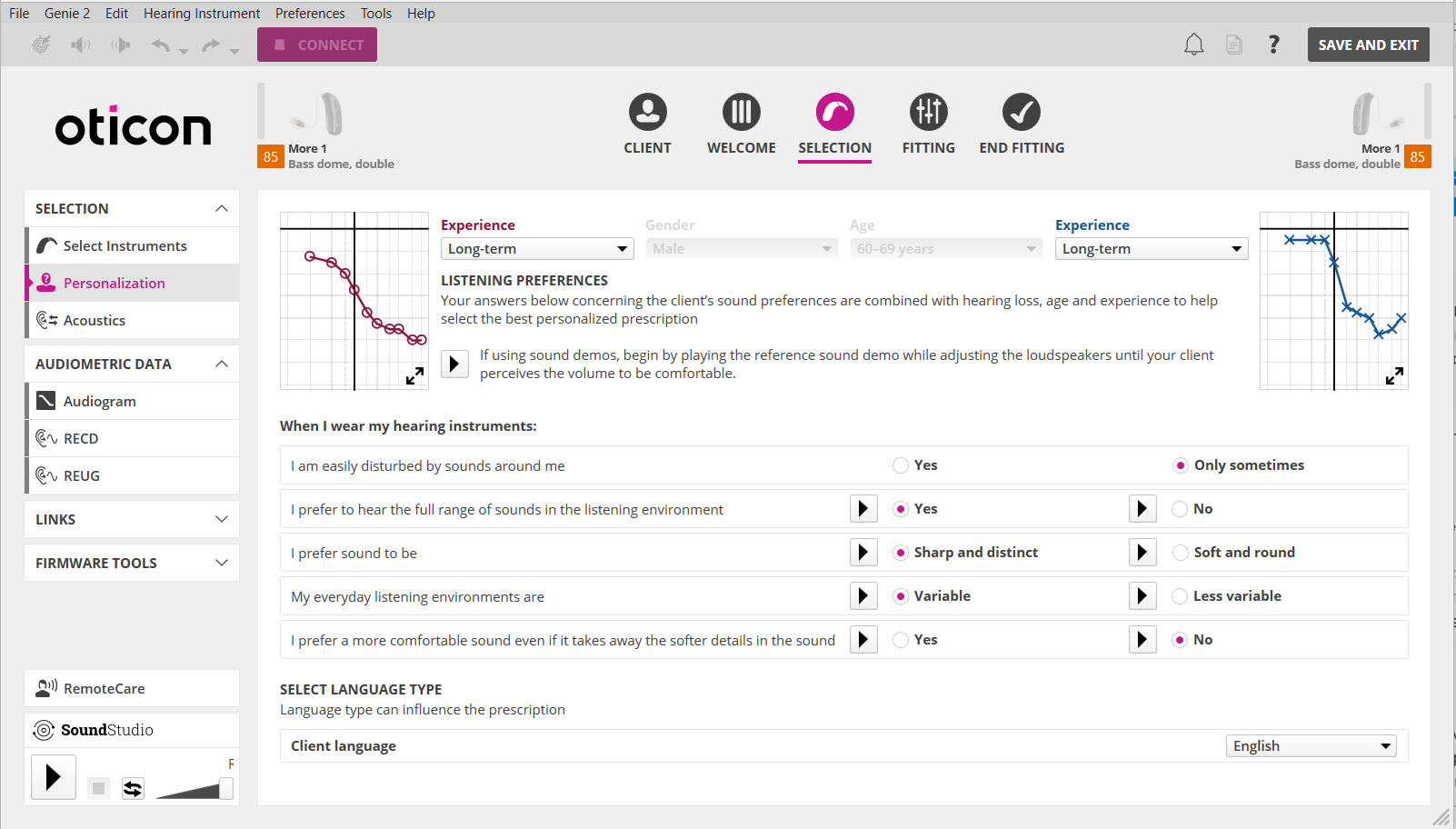
To your question “How does the aid know what helps the user needs (in terms of noise reduction) without feedback from the user?”, the answer is that it may take the answers you give it in the Personalization question (see screenshot below), which your audi should have gone over with you in your initial fitting, to formulate a judgement on how much noise reduction to apply. So there IS feedback from the user in the general sense. Beside this feedback, it may also incorporate its own judgement based on Oticon’s years of experience on how to rebalance a sound scene with the appropriate amount of speech-to-noise ratio, while in parallel allowing the user’s preference to factor in there as well. Also note that most likely, this Neural Noise Suppression is probably only activated dynamically when there’s speech going on. When there’s no speech detected in the sound scene, then the Neural Noise Suppression is probably de-activated on-the-fly to enable the “open” paradigm to work its magic in conjunction with the brain hearing concept.
What it looks like is that Oticon is doing a “double talk” on the issue of what to set the max value of the Neural Noise Suppression to. On the one hand, its online Help manual (see first and second screenshots below) tells you that the HA is smart enough to determine its own speech to noise ratio and will only apply the correct amount of noise suppression, up to the max level you set. If this is correct, it infers that you should set the max level to what your premium tier level HA is, which you paid the premium for, because why would you set it to less and cripple it to a lower tier level HA that commands a lower price? You might as well buy the lower priced premium level then, if you follow their recommended default.
On the other hand, the double talk is that Oticon is telling HCPs to leave it at their lower default values, because they know that there’s a price to pay for the max value → a muddier ambient sound. I guess they don’t want to advertise this “trade-off” publicly because it’ll probably prompt the public to consider much more seriously the More 2 tier instead of the More 1 tier, if the public deems that the trade-off of a muddier ambient sound is not worth the premium cost to pay for the More 1.
But if I had already paid the extra premium for the More 1 level HAs, I would still set the max Neural Noise Suppression to the highest value possible. My reasoning is that if it gets to be THAT noisy that the HA has to resort to setting close to or up to the max amount that my More 1 can handle, then I’d still rather have clearer speech even at the expense of a muddier environment. The Genie online help manual has consistently said that the HA will apply less noise reduction when the environment is less noisy, so there’s no reason for me to believe that I’ll always have a muddied ambient sound, and the only time I’ll have to deal with that is when I get into a Very Complex environment, and only when there’s speech going on.
You can read up on this topic in much more details in this thread if you want:


The default for the Environmental Configuration (and for most other stuff) is not necessarily the same for everybody. It depends on your hearing loss and the answers you give it in your Personalization setup that your audi is supposed to go through with you in the beginning during the initial fitting
Mine has a default of Complex (see screenshot below), while yours may have a different default, depending on your hearing loss and your Personalization answers.
