For me the music difference is probably the biggest thing. APD 3.0 is just so compressed and the way it alters the audio before it hits your ears changes music too much. The guitar feels muted and flat. I tried it again today. I don’t know if the pediatric formula will work for you if you have never used it before. I want to re-emphasize that I spent my entire life on this formula, and am very used to the loudness. I did want to give APD a chance because I get overstimulated in general and the idea of a quiet fitting is alluring to me… but not working.
Check out my audiogram and you will see: I’m beaten down with compression - not a lot of wiggle room for me even in the area of gain vs MPO. Sigh.
The good news is that hearing is relative to the person, and I do feel that music streamed via BT to my Android phone sounds FABULOUS in these Phonak Lumity Life 312s.
I don’t want to bring less optimistic news, but if your domes have significant slit leaks, the feedback threshold could be too low to achieve DSL 5.0 high-frequency target compared to NAL-NL2…
I noticed yesterday, in a pub with very few people in, that with DSL v5a Adult, the jukebox sounded “much fuller”. Sadly a quiet speaker (customer) was talking to me and I couldn’t understand a word. Upwards masking??
On the subject of guitar, there are a number of songs I stream that I’ve known (and played) for years. With APD, a lot of the guitar solos seem to be drowned out by the rhythm guitars. I certainly don’t remember it like this.
I like many things about DSL, if only I could have calm and speech in noise in APD, and music using DSL.
@OcramSagev@user490 Are you sure? I don’t think you can put custom programs on a different fitting formula in Target. If you could that would be insanely useful
I’ve been experimenting with Adaptive Phonak Digital 3.0 and DSL v5a. While watching TV, I couldn’t understand soft speech when fitted with DSL v5a. Using ADP at home, I can hear a 65 db police scanner 30ft away in a quiet 48db environment. Fitted with DSL v5a I can’t hear the scanner.
Upon closer exam, ADP 3.0 has more gain at G50 between 170 Hz and 4Khz; by as much as 11db between 1Khz and 2Khz. ADP also has more gain at G65.
I tried ADP 3.0 Semi-Linear compression, it sounded horrible during a phone conversation but perhaps it may have also been the connection of the opposite party’s equipment.
ADP 3.0 LINEAR was too harsh during action movies, i.e. The Avengers End Game. This hand me constantly lowering/raising TV volume.
DSL v5a sounds very good for bluetooth streaming of Spotify. The Beatles sound as I remembered in my youth.
That’s interesting. I’m pretty sure for me APD is lower in every frequency. With APD everything’s reduced by like ten db overall, and my gain looks like a rainbow with almost no gain towards low frequencies and high frequencies. With DSL 5 pediatric everything looks like one straight line across the whole thing and higher
Thanks to this thread I started experimenting with DSL 5 (Adult and Pediatric) vs the initial ADP fitting. So many things to try out. I also did an AD Direct which resulted in lower hearing loss values than my Audi fitted one. So far I am wondering if I should really try the pediatric?! I am 46 yr old and have hearing aids only for 1-2 months. Will set the current AD Direct audiogram shortly.
Also side qúestion - if I am doing AudiogramDirect and hold my ear canal closed with a finger, I can hear even lower decibels. Is that how I should be doing it, or without force-closing the ear canals?
Interesting responses I got from my comment.I never said Phonak Target allows multiple rationales in a fitting session. I think Oticon does.
My Autosense does not have a music program included, so I have to add one manually (this is because I have the lower tech infinio). Please consider this when reading the following:
So, here are the steps:
1.- OP said he created a session with NAL-NA2.
2.- OP said he created a session with DSLv5.
3.- Open the DSLv5 session:
3.1 Go to → Fine Fittings → additional programs → music tab (if it is not there, create it). Phonak Target auto-populates the music program.
3.2. Select the tab [Gain & MPO] in the music program.
3.3. Take a screenshot of both the insertion gain vs frequency chart and the table below. Please note that there are multiple ways to display the number of fittings bands, so you may want to take more than one screenshot to capture as many fitting bands as possible. Please include the CR values in your screenshot.
3.4. Print your screenshots.
3.5 Close session
4.- Open NAL-NA2 session.
4.1 Go to the fine tuning → additional programs ->_music (if not there, create one under additional programs).
4.2 Go to Gain & MPO
4.3 Modify the values so they match the screenshots you took. CR values will automatically change as you do this, please compare to the values to the ones you have on the screenshot.
4.4 There! Now you have a music program BASED on a DSLv5 rationale.
I am not sure if there is something “under the hood” even when you set the same gains and CRs. There is possibly another differences than gains and CR, probably, among others, attack/release time, etc.
I don’t either @Bimodal_user , that’s why I was careful to say “BASED”.
It is the music program, where almost all features are pretty much turned off anyway in Target.
My approach to DIY : Trying different settings is faster than trying to figure out in advance if they are going to work or not.
I’ve found that doing such things during Audogram Direct and Feedback Real ear has been counter productive. Just allow programming above estimated feedback level.
When you do Audiogram Direct, the measuring point is from the Feedback/Real ear test. If you mess with it, it just won’t work properly.
On my Outputs the high frequency difference in MPOs is negligible, probably due to either the capabilities of the hearing aid, or feedback suppression.
I’m interested in experimenting with using DSL v5a Adult, but changing the MPOs in general settings to APD, except in Music. This might give me best of both worlds. Less compression, and clarity in speech, then using Music for just that!
The in-situ audiograms take into account the dome selection and the feedback test, among other variables. In other words, the vent effect . Putting fingers in your ears changes one of the inputs needed by the software.
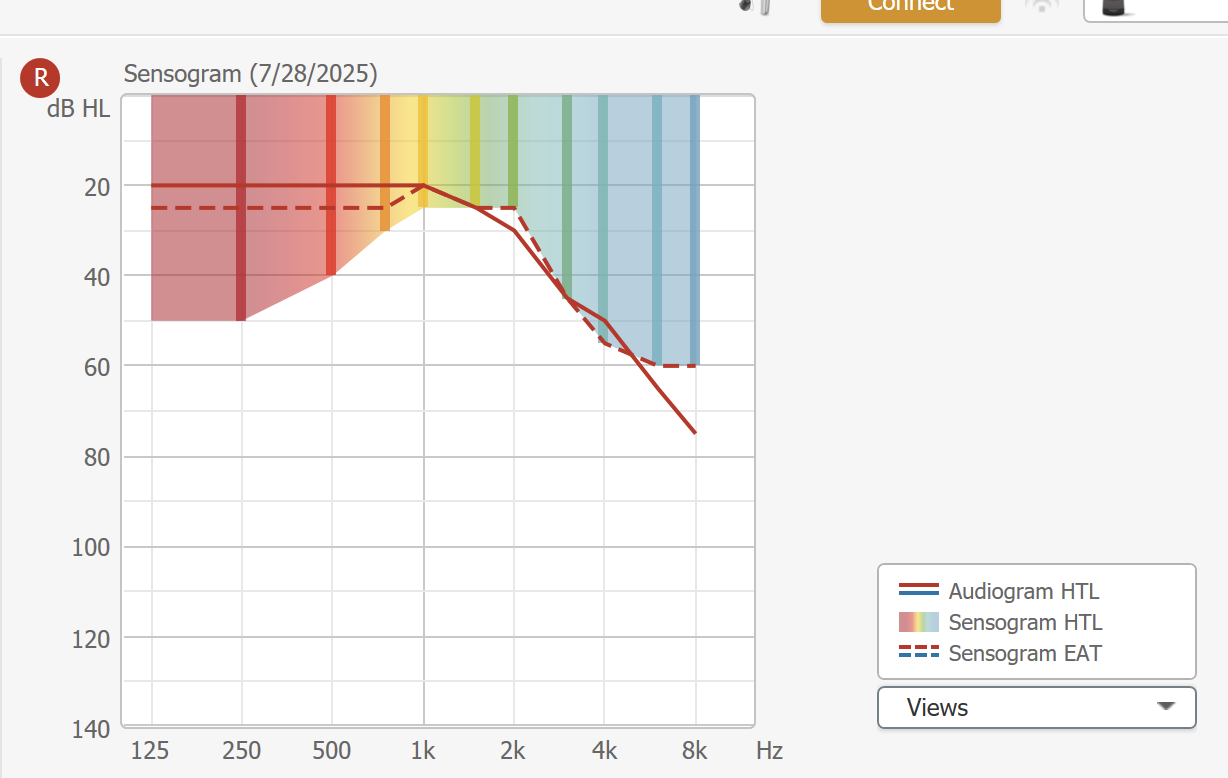
The difference between in-situ vs standard test is also computed in the software. Widex, for example, shows the Equivalent Adult Threshold (EAT) and the Hearing Threshold levels (HTL) when doing a sensogram (their term for in-situ test) (see chart below). The HTL is the measurement with aids, EAT is from the standard audiogram. The computed EAT , calculated by the SW may not be accurate at certain frequencies. For example, in my case, the computed EAT is not the same as the HTL at low frequencies) but that is because I did the test with openbass domes (which leaks low frequency sounds). The software knows this and did not recommend added gain below 1K.
So, in short, there is an algorithm that takes into account these variations. Some will not follow these calculations and go straight to REM, others say in-situ is enough. I think that horse has been beaten a lot in this forum