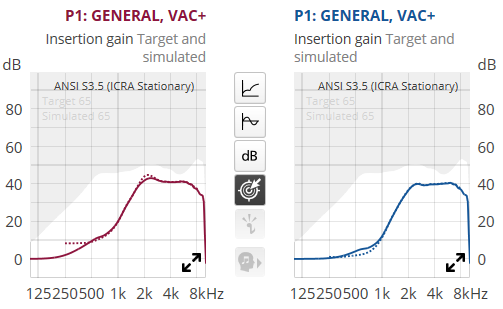
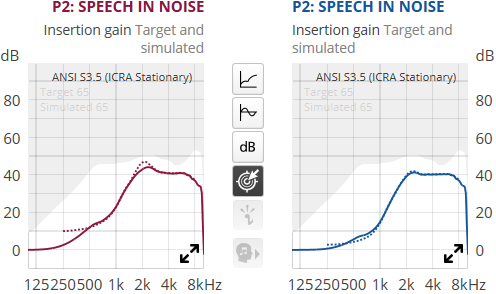
That’s very true that if you’re in very complex environment where there are a ton of people around such that almost everything is speech, overwhelming anything else that may be noise, then it’s not good either because very little would be suppressed, and if the Sound Enhancer is set to Detail, that will raise the speech volume to even louder.
I wonder if in that situation, the user would turn on the MoreSound Booster in the ON app to narrow the directional beam forming to just the front only would be more helpful than using either the Speech in Noise or the default program P1?
I also wonder if just turning down the overall volume compensate for the increase in gain in all the voices helps, at least to reduce the discomfort of the very loud volume of all the cumulative voices.
Another thing is that if Oticon has trained 12 million sound scenes in the DNN, I wonder how many of these sound scenes are of the type where you’re in a crowded bar or a coffee house, or the hallway of a theater during a break where everyone crowds out to the hallway and talk. And if they have included these scenarios in their 12 million sound scene, what the DNN outcome is like for them.
It’s one thing to be in a crowded restaurant where at least you’re still spaced out enough by table groupings to try manage separate group conversations. It’s another thing to be standing shoulder to shoulder with a sea of people in a tight space like a theater hallway during a break, where everyone is talking at the same time and the ceiling is extremely high and the echoes permeate and made worse by the high ceiling. Heck, I don’t even know how normal hearing manage those scenarios, but apparently they do OK because they’re all talking and listening and the conversations do carry on.