@colorrama88: Thank you for your recent, helpful posts! The quote above is revealing, and right on the money. Guitarists in general, and acoustic guitarists, in particular, don’t talk in these terms, but - perhaps they should.
[Nota: The objective of this post is to describe, in analogue terms, the importance of linear gain and compression in creating a balanced and pleasant musical experience, as opposed to listening to speech. It’s not intended to be an off-topic , tangential discussion of guitars.]
Please, bear with me as I give a short example related to one of my instruments, which I play with the guitar situated on my lap, soundboard facing 180° away from me. (It’s a C F Martin forward-shifted, 1/4" scalloped-braced herringbone D-35.)
For non-guitar-players, this is a guitar with a big soundbox. The internal bracing of this box is thinner, and more delicate (therefore more responsive) than conventionally-braced models. The positioning (shifting forward) of these braces inside the instrument creates a much larger section of unsupported top table between where the strings are connected (the bridge) and the end pin, where the strap connects.
This can be good and bad: if one is unlucky, the top of an instrument built on this pattern can vibrate in such a way that it interferes with itself. In this case, some notes sound louder than others, while others fade away far more rapidly than their neighbours, which continue to ring, after they are plucked. (If you’re lucky, and have a good specimen, the opposite is true, and the guitar will play with equal loudness and resonance across its entire useable range.)
My HD-35 is one of those exceptional instruments that sounds totally linear, from its lowest note to the highest. No one note predominates over any other, and there’s no interference, or phase cancellation occurring either on the top table, or anywhere else in the internal latticework that supports the guitar. The result is that each note and chord seems to “bloom” - when you touch the instrument, which is entirely acoustic. It responds instantly when touched softly, but the sound takes a long time to die away.
Here’s where compression comes into play, and where the synergy or interdependence of frequencies that comprise the tone are also important - if one strikes the strings of this instrument really forcefully, it will, of course, sound louder, but - only up to a certain point! It appears to be self-limiting. You can’t get it to produce a super-loud, strident peak, because there’s actually an analogue compression phenomenon happening. The vibrating top of the guitar is literally compressing the air inside the body and creating a back pressure that effectively dampens the notes whose attack volume would otherwise be too great.
And that same volume of air that’s trapped inside the instruments has a bit of a natural tendency to resonate, like when you slap on the side of a plastic 45 gallon drum. This natural resonance actually makes very softly-played notes to sound louder than one would expect them to be, given how little energy is being used to strike the strings. This is the other side of compression.
Electronic compression is, I suppose, trying to accomplish pretty much the same thing - attenuate the loudest notes, so they don’t overwhelm the rest, and permit the softest notes to speak loudly enough that they can be heard. It’s much more complicated than this, of course, but you can grasp the gist of it.
The key thing here is that everyone, without exception, that sits in front of my Martin and listens to it sing, appreciates the quality of its voice. That’s because the guitar is totally linear, and also possesses just the right amount of natural, analogue compression. And that’s why I understand and appreciate @colorrama88’s quote about his Starkey instruments being linear.
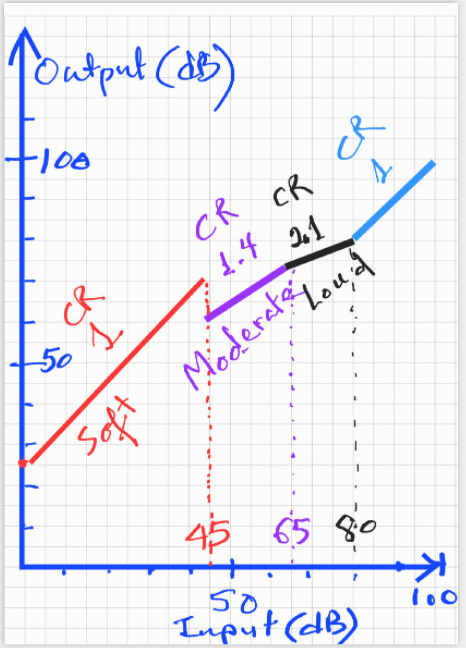
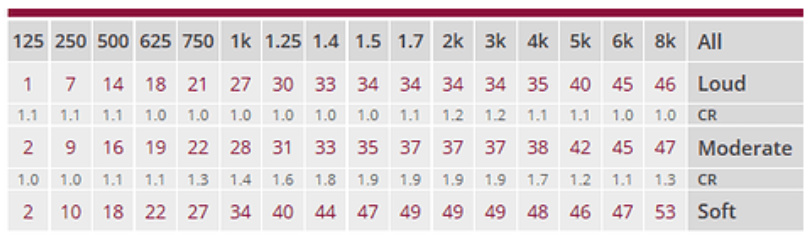
So, while the engineers may be vastly improving our comprehension of speech by applying different amounts of compression and gain to different frequency bands, as articulated by @Volusiano, when it comes to the sound of Music, our brains seem to be hardwired to prefer - (here it comes!) - linearity (which is, BTW, one of the principal failings I an hear in the MyMusic program.)
All we’re asking for is a native music program that works, in addition to the other amazing programs that allow us to understand soft-spoken children or pick out friends’ conversation in a crowded restaurant! So perhaps the HA industry should just acknowledge that musicians and “speechies” are potatoes and pears, and give us a device that will allow us to choose which mode is of greater importance to us, at a given instant in time, rather than pretending like one shoe fits all.
[This is only my opinion, YMMV.]