Very good point you raised here @user246 that Philips may apply beam forming more aggressively to put more focus to speech on the front in the “no motion” and “occasional motion” situation, compared to how Oticon does it (which may put less emphasis on beam forming due to their open paradigm). However, I suspect that the intent interpretation between the 2 brands are probably not too far off from each other, simply because there’s really not much else you can interpret from the head movements beside this. By doing any deeper interpretation beyond this simple “generalization”, it would be too far reaching and can have the opposite effect of doing a bad interpretation.
Anyway, having the open paradigm doesn’t imply that Oticon doesn’t do beam forming. Oticon may choose to do beam forming differently and less aggressively, but they do use beam forming, based on the 2 observations below:
-
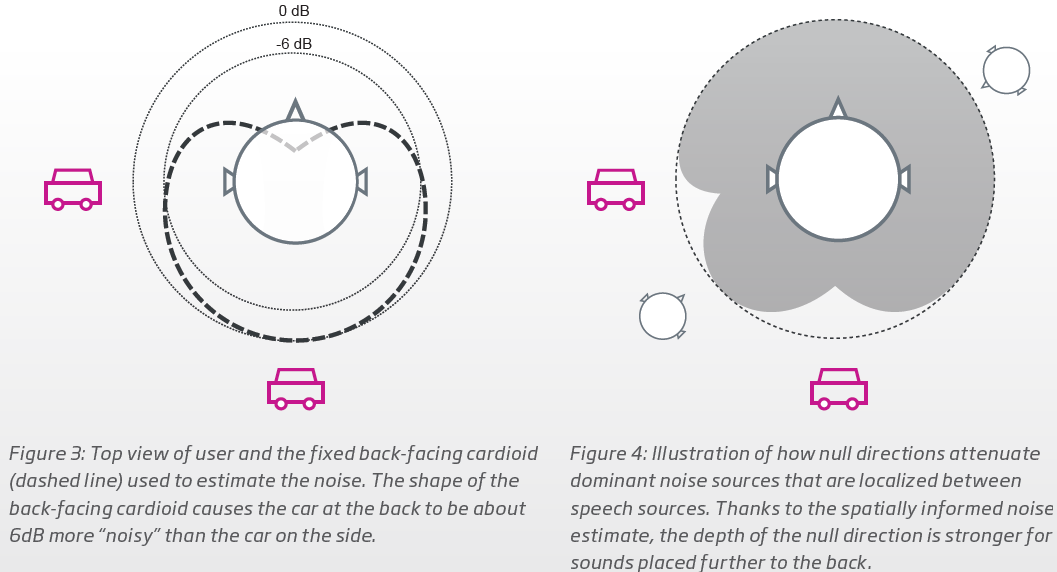
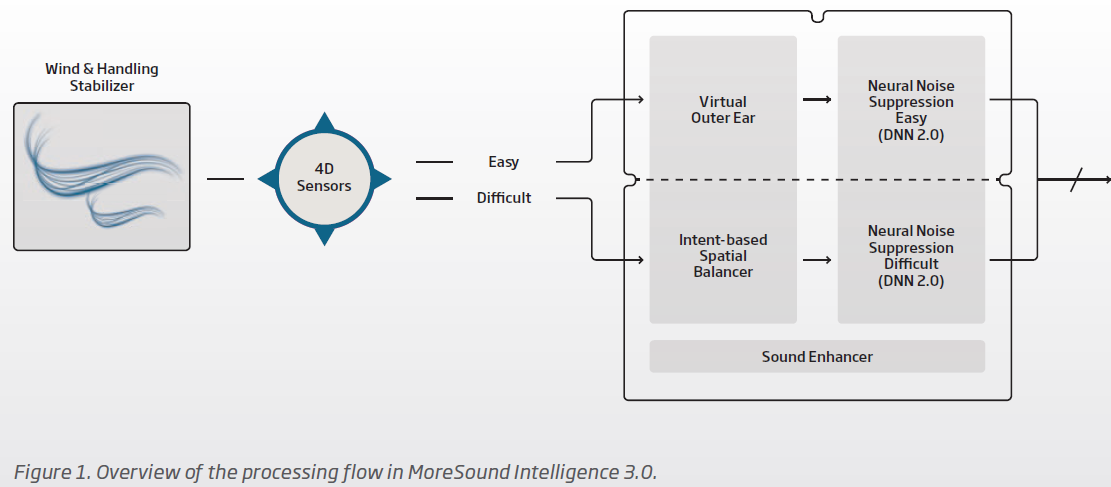
The Oticon whitepaper since day 1 (of the OPN era) until now always mentioned the MVDR (minimum-variance distortionless response) beam forming technique to create a bigger contrast between meaningful and less meaningful sounds. The first screenshot (from the OPN whitepaper) below are the 2 illustrations of how the null directions are formed using 2 types of polar signals for droning noise sources like a car. The second screenshot is the verbage explaining how this beam forming works. Note that it’s titled “Intent-based Spatial Balancer”, implying that before it was just a simpler balancer, but now, there’s an input component to it that is based on the 4D sensor. Unfortunately, Oticon didn’t go into details of now the 4D sensor input drives the MVDR beam forming.
-
For the Difficult Environment classification, This Intent-based Spacial Balancer is placed squarely right before the DDN Neural Noise Suppression feature (see third screenshot below). After the Spatial Balancer does its own noise attenuation to balance the sound scene better, the DNN take this input and does its own noise reduction for speech specifically. The noise reduction by the DNN is not beam forming based using microphone plotting techniques anymore, but it’s just about varying the volume levels of the different sound components in the sound scene that the DNN has broken down and recreated, to achieve the SNR for speech contrast by giving higher volumes to speech components and lower volume to other non-speech sound components.
Because the Directionality Setting in Genie 2’s MoreSound Intelligence window has 3 possible values: 1. Neural Automatic, 2. Full Directional, and 3. Fixed Omni, this implies that the DNN can place localization information on the sound components. Before, in the Real, without the 4D sensor, the DNN probably just gives better SNR contrast to speeches coming from anywhere, not just in front. But now, in the Intent with the 4D sensor, the DNN can use this information to apply various SNR contrasts for various speeches differently, depending on where they come from in the sound scene, based on the interpreted intent using the 4D sensor on the head movement.
So going back to @user246 's great observation that the Philips 9050 probably uses beam-forming to execute the interpretation of the user’s guessed intent for speeches, but the Oticon Intent probably doesn’t. The Oticon Intent’s DNN can still execute the same interpretation of the user’s guessed intent for speeches, not any differently than the Philips 9050, except without needing to use beam forming, but simply by rebalancing the volumes of the various speech components it has broken down and rebuilt in its sound scene. Because the Philips 9050 and the Bernafon Encanta don’t have the DNN like the Oticon Intent, it’s likely that the earlier 2 use beam forming to execute the intent interpretation, while the later uses the DNN to do it.
But the main point is that I think it’s unlikely that the Philips 9050’s intent interpretation would be any different than the Oticon Intent’s interpretation, nor any different than the Bernafon Encanta’s interpretation. There’s only so much you can deduce from the head movement sensors, so the goal should be to keep the interpretation simple enough and generalized enough so that you don’t over-guess the intent incorrectly, which can backfire in embarrassing ways.