Although “noise” is mentioned a lot in the Oticon whitepaper on MoreSound Intelligence (the deep neural network stuff), there’s no clear definition of what noise is. This is to be expected because especially in the open paradigm, a sound can be noise to one person and of interest to another person. Even to the same person, a sound can be noise at one time and be of interest at another time.
But maybe I can tell you how Oticon treats sounds as noise sources in their MoreSound Intelligence flow (the deep neural network stuff) as seen in the screenshot below.
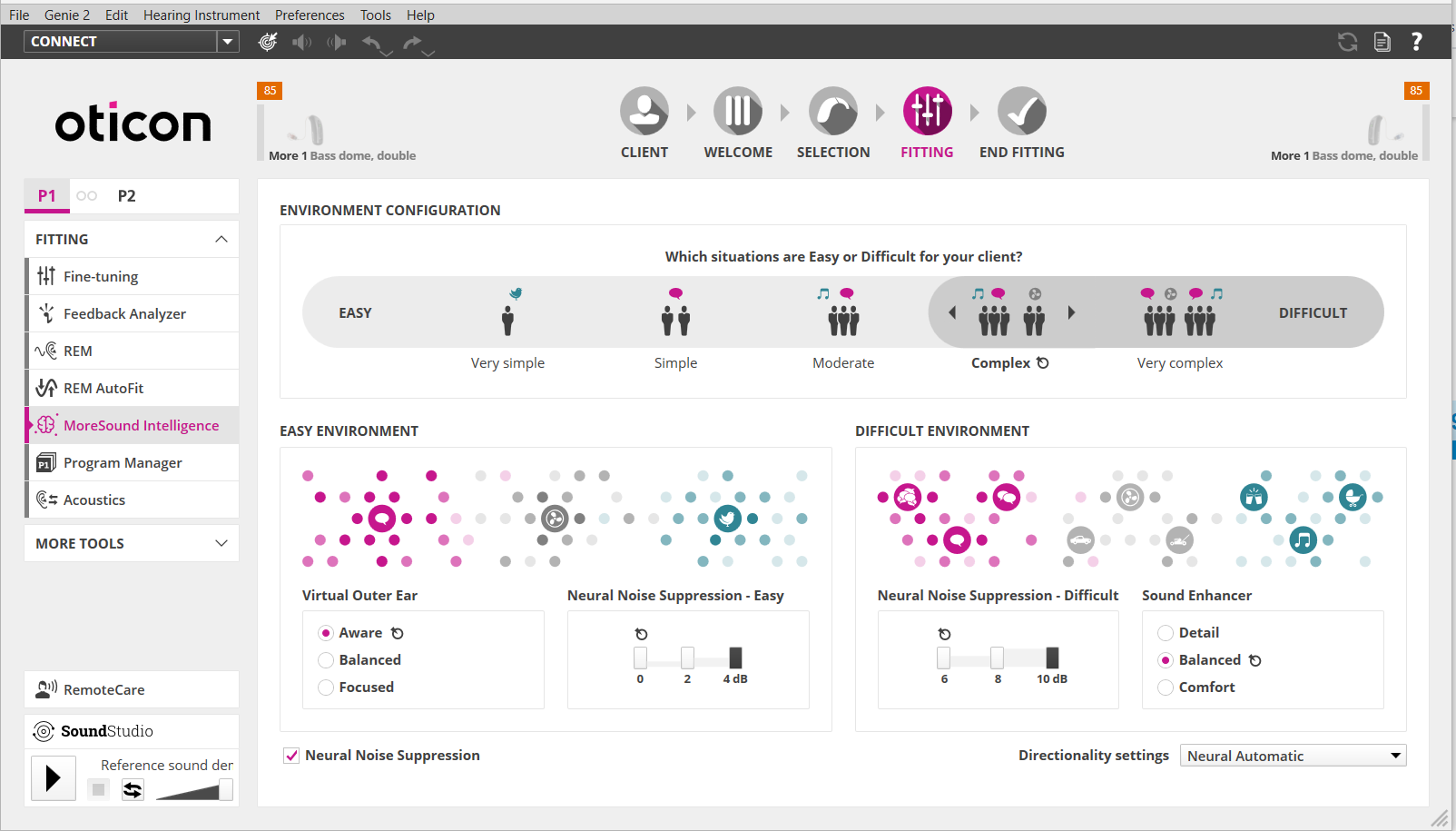
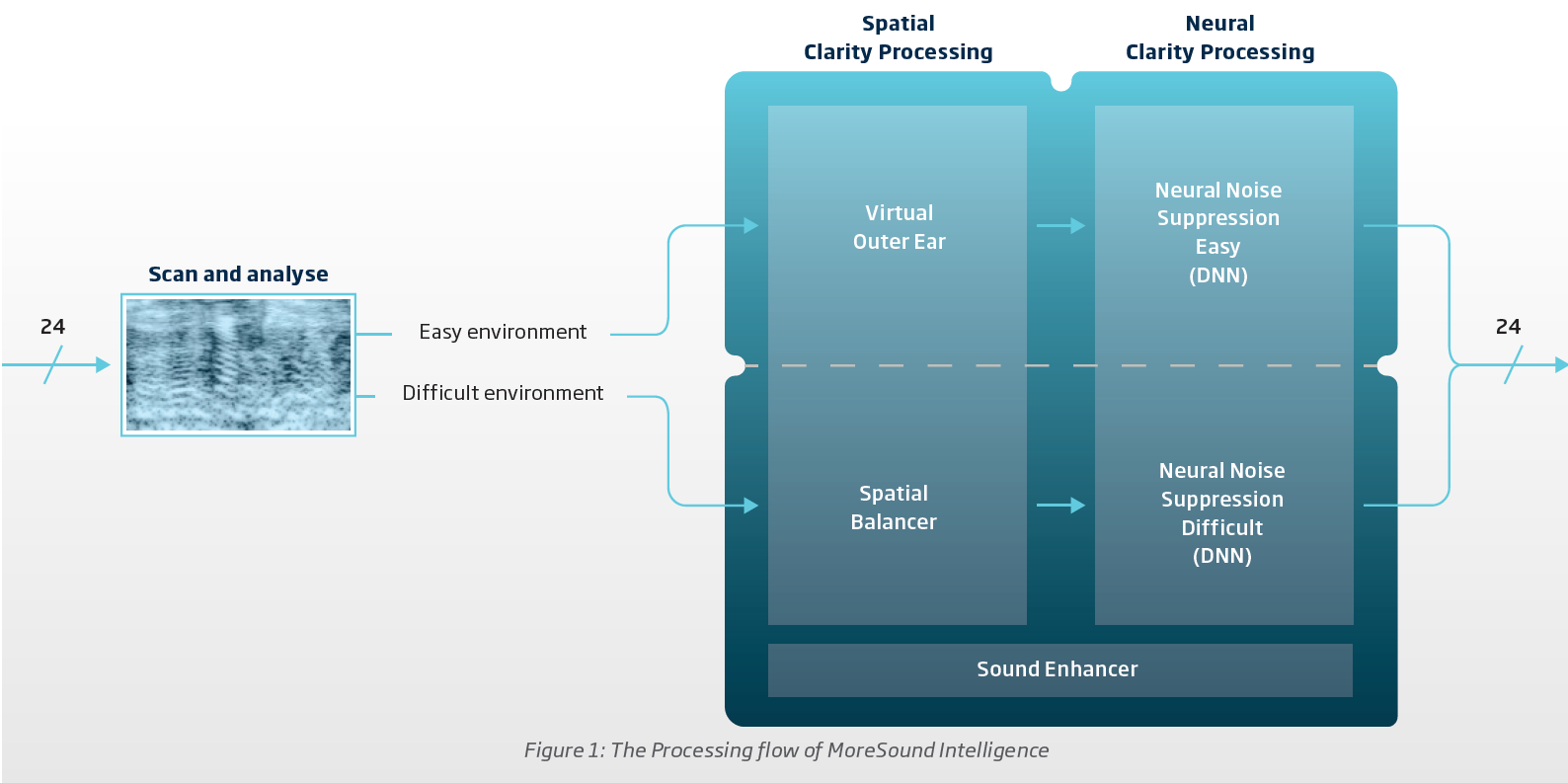
In the Scan and Analyze module, they just look at the amount of sounds in a sound scene (every 1/500 seconds) to see how much sounds there is. Then based on the user input in Genie 2 on what the user think is Easy and Difficult, it’ll route the sound scene to either the top flow for Easy or the bottom flow for Difficult.
Noise is not a concern in the Easy Environment, so the Virtual Outer Ear with 3 different models is used to obtain spatial clarity without really attenuating any noise.
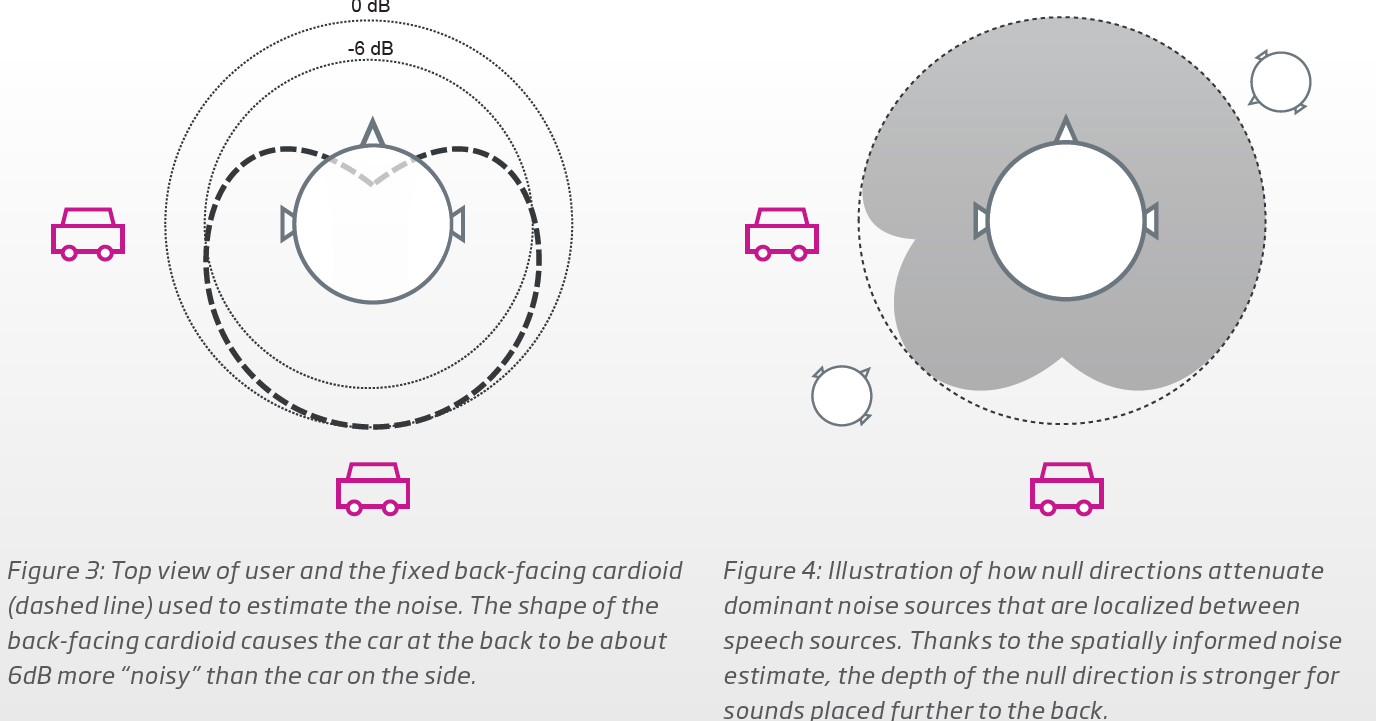
Noise is a concern in the Difficult Environment, so Oticon uses what they call a Spatial Balancer. It’s basically the same stuff they use in the OPN OpenSound Navigator to attenuate surrounding noise. It uses 2 types of mics, an omni (all around) mic, and a back-facing cardiod mic, and mix them up to attenuate noises from the sides and behind to favor speech. So in this case, noise is any sound from the sides and behind that is not speech, but in the presence of speech. If there’s no presence of speech (checked every 1/500 times per second), then the other sounds don’t get attenuated and you would hear them. In summary, this Spatial Balancer is basically a directionality system that uses a special type of beamformer to rebalance the soundscape in favor of speech, but only when speech is present. See the 2 figures in the second screenshot showing how the noise attenuation is done inside the Spatial Balancer.
Finally, after doing some “preliminary” noise attenuation via the Spatial Balancer, the soundscape goes into the deep neural network for processing. This AI has been trained to differentiate between speech and non-speech sounds, and trained to provide a balanced sound scene between all the sounds at that moment based on real life examples (12 millions of them) When you tweak the Neural Noise Suppression here in terms of dB, you’re effectively tweaking this balanced sound scene further, more in favor of speech and attenuating the other non-speech sounds (which is now considered as noise), but only if speech is present. If speech is not present, you get your normal balanced sound scene just the same. The higher max value you assigned in Genie 2 for the Neural Noise Suppression, the more leeway you’re giving the More to be as aggressive in the attenuation of the noise as needed, up to the max. But if there’s no speech, or only single speech, the attenuation of the noise should not be employed by the More the max. The More is supposed to attenuate less if less is needed, and more only if more is needed, up to the max set.
Having given you a long winded explanation, back to your original question of what can be done to understand your wife in the car better over road noise at highway speed? I think setting the Neural Noise Suppression value to max and include Moderate (or even Simple to begin with then ease back to Moderate later) as part of the Difficult Environment when your audi program Genie 2 for you can help.
But remember that this help from the More is only while your wife is speaking. As soon as she stops speaking, the road noise will come roaring back. So the other half of the equation (beside the help from the More) is your brain hearing acuity development over time, so that you can learn to tolerate the road noise when your wife is not speaking, and focus in as soon as your wife starts speaking. Some people get adapted to this quickly and thrive. Others just want the peace and quiet of no road noise even if their wife is not talking to them → these people are probably much happier with the traditional paradigm instead of the open paradigm.


 Okay … well, that’s very useful to know. Thanks to both
Okay … well, that’s very useful to know. Thanks to both  ].
].