Of course this is highly proprietary information for Oticon, and naturally even the whitepaper doesn’t go into this level of details.
But if I have to make an educated guess, the captured data is 12 million sound scenes, so each sound scene has to be used as input as well as the golden reference to compare the DNN output against, because after all, that’s really all they have, the 12 million recorded sound scenes.
So my guess is that the DNN is trained to break down the sounds in a sound scene into discrete sound components, then rebuild the sound scene as accurately as possible compared to the original sound scene that was fed in as the input, but this time the “rebuild” is no longer in the form like the original aggregate, but now using the discrete sound components to rebuild it instead, and recreating the appropriate volume levels, as well as localization of all the sound components, and whatever else is involved.
Again, this is only a guess on my part, it’s not what Oticon has revealed. They’re naturally very tight-lipped on this. But it seems consistent with the idea that they want to be able to break down, isolate/localize and identify sound components in a very discrete way, so that they can manipulate and rebalance the sound scene any way they want using these sound components (per the user’s settings in Genie 2), to prioritize speech, yes, but also to ensure that all the sound components can be heard if listened to, in order to fulfill the promise of the open paradigm.
Back to the DNN training, this “rebuilt” sound scene (which is the output of the DNN) is compared against the original/golden/reference sound scene, and the differences between the two are measured. Then this data (of the differences) are propagated back into the DNN, and the neurons’ weights and biases are mathematically and recursively re-adjusted to values that would minimize the differences that were back-propagated, then the whole thing gets propagated forward again to arrive at an outcome that yields the least/minimal differences against the golden reference, although in the beginning with not enough training data going through yet, the differences are probably still quite large because the DNN is not quite fine tuned yet.
Then the next sound scene is fed in, and the process above is repeated. You do this enough time, eventually the neurons’ weights and biases can be tweaked enough (but hopefully tweaked to a lesser and lesser degree each time) to generate an accurate enough outcome in the end for all the trained data.
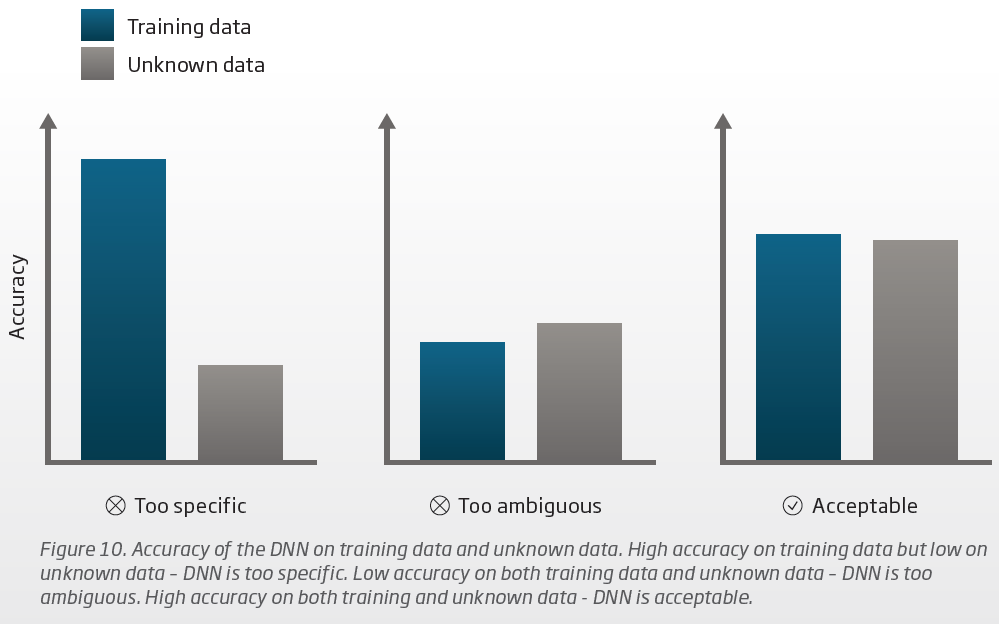
However, if your original DNN structure is not well designed in the first place, then the result is still no good in the real world. One version of the DNN design may be trained and proven to be very accurate with the training data, but when fed in “unknown” data (which is basically the real world data), it’s still not accurate with the unknown data. Such is the case in the left most graph in the screenshot below. This DNN design version is too specific to the training data but still perform poorly on the unknow and therefore not acceptable.
Another version of the DNN design may not become very accurate no matter how much you train it (because it’s a bad design in the first place). In this case (the middle graph in the screenshot below), it ends up not being very accurate with either the training data or the unknown data. So it’s considered a design that’s too ambiguous and is no good either.
The whitepaper mentioned that Oticon actually had to play around with several different versions of the DNN design, and went through the testing phase to scrutinize and find a design would be optimally and adequately accurate enough for both the training data and the unknown data, and chose this to be the final version of the DNN design. This would be the third graph on the right of the screenshot below.
Needless to say, this implies that not all 12 millions sound scenes were used to train the DNN. Part of them were used for training, and the remaining were used for testing, as the “unknown” data.