I’m also surprised to hear that @x475aws has more than two program slots. I am quite sure the the Whisper audi told me that there was only a possibility of two program slots. Maybe that audi was wrong. If so, I apologize for providing incorrect information to @happymach.
@ziploc/ Is it possible that [Edit:] the Brain is in some sort of Beta test mode, and Whisper is trying out different brain hardware on different Brain Trust clients before finalizing the mass market version?
(This is posed as a legitimate question, as Whisper doubtless has several smartphone manufacturers courting it for their business, which could be significant.)
@Volusiano, it may take me a couple of posts to answer your questions. The Mores are set up so that Open Sound Booster is on all the time.
The Whispers seem just as “open”” as the Mores, if not more so. The mid-rangey tone of the Whispers might have something to do with that.
Subjectively, it seemed to me like when I encountered the crowded kitchen with everyone talking at once, the Mores jumbled everything together into a cacophony where I had to listen very hard to pick up individual voices. The Whispers took the same soundscape and made it sound like there were several conversations going on at once, and I could choose which one to concentrate on. Kind of like normal hearing. To be sure, the Whispers did not do this perfectly, and it was still a difficult environment. But the difference was pretty striking.
The prospect of frequent AI software updates is promising too. But I wonder if the update process will (or already has) encounter the law of diminishing returns, with each new update delivering less-dramatic improvements than the last.
I have the Dynamic setting, and two Environments under the Custom setting. Here are app screenshots:
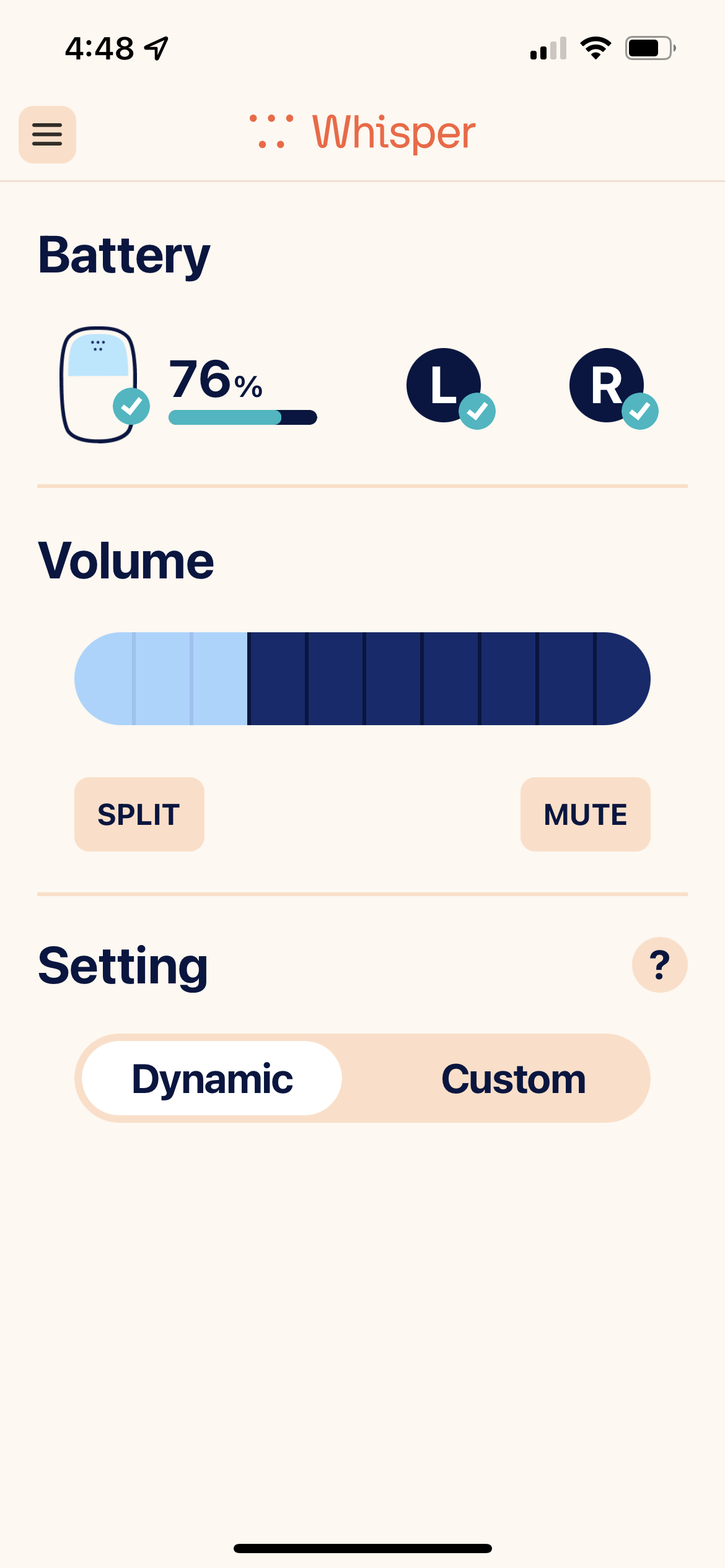
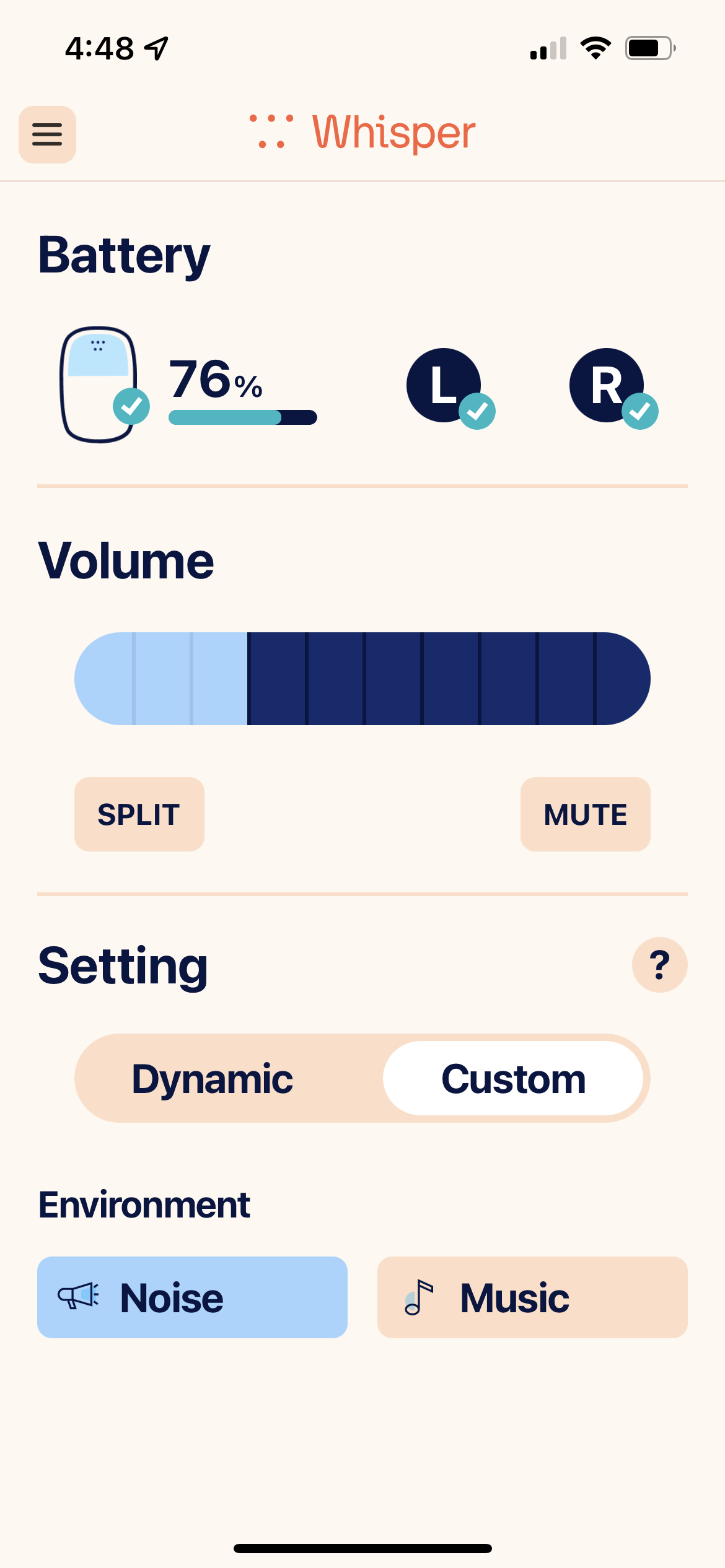
@Volusiano, it seemed like the Whispers were accomplishing the perceived separation of voices through a different process than directionality. I could easily imagine that Whisper’s “voice separation engine” was creating this effect.
Of course, if one is aware that something is expected to happen and is listening for it to happen, and HOPES it will happen, it makes it much more likely that one will perceive it to be happening. Could that have been happening to me? Absolutely possible. But all I can do is report what I hear and what I feel about it.
that’s pretty limited. I wonder why so few programs are available?
@x475aws, ok now I see what you mean. Yes, in that sense I do have three programs: dynamic, and under “Custom “ two environments I can toggle between: noise and music.
1 Like
Exactly! There are 3: Dynamic, then Custom. Within Custom there are 2 “environments.” Currently, I have “Noise” and “Music”.
Because you really don’t need them. That’s the way it should be, IMHO.
Were you using Dynamic or Noise?
Mostly using dynamic. I switched to custom (noise) a few times and left it there if it helped, or changed back to dynamic if it didn’t.
That is exactcly the opposite effect of what the Oticon rep described to me when NNS Difficult is set to 10dB.
All background noise should be somewhat "Muffled"sounding, and the primary conversation should be pronounced.
That seems like a real conflict. Betwqeen NNS at 10 & More Sound Booster, sounds to me like chaos!
@ziploc, this just doesn’t sound right to me. First of all, the MoreSound Booster is a feature that’s only available in the ON app and has to be enabled/disabled by you, so I struggle to understand how you have it set up “all the times”? Or do you mean that your audi and/or the Oticon rep created the equivalent of the MoreSound Booster version into your default program P1?
Secondly, can you elaborate on what they do exactly in your P1 program to make it the equivalent of the MoreSound Booster?
Thirdly, why would you want the MoreSound Booster equivalent in your P1 program all the times in the first place? The reason Oticon make it an option that requires users to turn on/off themselves in the ON app is because Oticon doesn’t want users to use it all the times. They want users to use it only as a last resort when they really struggle with speech in noise in very complex environment, so they set it up that way. I wonder if your having the equivalent MoreSound Booster on all the times might have messed up how your More is truly intended to work in the first place?
Fourthly (and finally), Oticon has been giving users very conflicting information about how the MoreSound Booster works. The details are too much to share here, but if you’re interested in learning more, below is the link starting at post 99 that goes into details what I’m talking about here (which spills over to another thread in the second link below that starts at post 58. So what I’m saying is that I don’t even know whom/what to believe when trying to understand from Oticon how the MoreSound Booster works anymore. So I would go to great pains not to turn it into a permanent feature in your default P1 program, but would use it sparingly via the ON app switch only when I have difficulty with SIN to see if it helps or not.
2 Likes
I don’t think a tweak on the margins is going to bridge the gap between More’s performance in noise and Whisper’s. If you still believe the Brain is a marketing gimmick and can’t explain Whisper’s performance, consider this quote from one of their white papers:
“While Whisper can directly enhance a 4 ms segment of audio in 3.7 ms using billions of operations, the processor in a leading competitor would take 2,800 ms to perform this same task. Because running an algorithm hundreds of times per second is a requirement to enhance audio in the tight latency requirement of a premium hearing device, it is impossible for a legacy device to run a deep learning algorithm of this size and capability.”
At 3.7 ms per 4 ms segment, Whisper can keep up with the sound while doing the referenced enhancement. At 2,800 ms per 4 ms segment, the processor in a “leading competitor” can’t keep up.
This is a marketing white paper and thus inherently suspect. But it makes sense to me, someone with extensive coding experience, albeit none of it involving signal processing.
At this point the interesting questions for me are: Now that you’ve seen good reason to believe that Whisper supports speech-in-noise better than legacy hearing aids, do you have an ethical obligation, as an influencer on this forum who regularly offers detailed information and advice about hearing aids, to disseminate this information to people seeking help? And do you have an ethical obligation, as an influencer, to try Whisper yourself?
3 Likes
Who are you addressing this question to? Just in general or to a particular individual or group of individuals?
I’m sorry, I meant to reply to you.
I would contend that based on the anecdotal data point from only 4 Whisper trialers so far, there’s no good reason to proclaim that anything is conclusive like you think it is. There are tens of thousand of folks using legacy hearing aids, from the Phonak models to the Oticon models to the Widex to Starkey to the Sivantos to the Resound who are perfectly happy with their HAs and don’t need to try out anything else, much less Whisper.
And I’ve already explained that there are many ways to skin a cat, so to speak. Whisper decides to skin the cat the hard way, while the others used an easier way to skin the cat. I gave several examples, but I guess you don’t want to hear it or understand it. The others spent their resources and development cycle to train their DNN up front then condensed it into a formula-like result then implement this result much more easily into the HAs. Whisper meanwhile chooses to do it the hard way and that’s why they need the kind of power and resources that require a brain to implement and execute. So you can quote all the Whisper information you want about how only they can process that kind of data in real time and nobody else can, it’s not going to convince me any more or less because nobody else needs to do it the way Whisper chose to do it, so they don’t need the kind of power and resources that Whisper does in real time. They only have to invest their heavily resourced development cycle up front offline, where it belongs, then only implement the condensed result for users to benefit from.
I’ll give you a couple more examples, in case the others that I gave before went over your head. You can have 10 guys to move a large rock or you can use a smart lever system to move the same rock with just one guy. Here’s another example, you can use calculus to figure out the area of an irregular shape quickly, or you can cut that area into a thousand rectangles and add up the total area of those thousand rectangles manually. Why would the others do things the way Whisper chooses to do it if they can do it in a much smarter and easier way? Albeit they may have to invest a lot up front to develop and figure out the calculus equation offline (analogy here to the 12M sound scenes collection and training going on behind the scene offline up front), but once they can condense it into a formula, the implementation is no longer a monumental task like Whisper makes it out to be.
The only ethical obligation I have is to speak my mind about what I think, not what somebody else tries to convince me to believe in. And what I think is that even if (big IF, not yet proven by an underwhelming anecdotal evidence of 4 individuals compared to thousands of other happy users from the big 6) Whisper indeed does have a superior SIN to the legacy HAs, as long as most users are fairly (even if not totally) happy with the SIN performance they get from their legacy HAs, then this “marginal” SIN improvement that Whisper “may” be able to deliver really can’t outweigh what many consider deal breakers from the Whisper system: 1) the need to carry a brain, 2) the subscription system where you have nothing to show after 3 years, 3) the outrageous lease price of $179/month even if you can get half of that lease price on discount in the first 3 years.
If Whisper approaches me and offer to let me try out their system for free without any burden to anyone, then I’m all game and I would be willing to try it out and give my honest opinion. But I’m not going to make an effort to seek out an HCP associated with Whisper to see if they may or may not charge me a fitting fee to try out the Whisper and cause an inconvenience and waste of time for them and me to find it out, because unlike the 4 Whisper trialers, I’m perfectly happy with my OPN 1 and don’t need to seek out a better SIN solution even though I don’t consider the OPN 1 to meet the SIN holy grail either.
4 Likes
I don’t think this analysis of the differences between the two systems is correct. From my own reading of the Whisper documentation, I’ve taken away that both brands have DNNs that are trained “up front.” What is different from about Whisper’s design is that the resulting signal-processing model is updated with every firmware cycle (every 3 months), perhaps on the basis of user-recorded data, whereas Oticon’s is more or less set in silicon and unchangeable. In addition, Whisper’s signal processing model itself appears to involve more complex (i.e more CPU intensive) real-time treatment of sound, involving more “points” of fit.
Phrased using your terms, the “formula-like result” is less “condensed” and therefore more precise on the Whispers.
There may be an analogy with the computational photography powering the best smartphones: the processing model is established up front through extensive sampling and testing via DNN techniques, but what makes the difference now is that the model itself is more complex, have been enabled by the vastly more powerful current CPUs (Apple’s CPUs have dedicated “neural engine” sections on the chip, whose performance is overall in the teraflop range). These CPUs are still too large and power hungry to fit inside a hearing aid, but they do fit inside a “brain” unit which is a bit smaller than a smartphone.
@Volusiano also neglected to mention the disadvantage of non-rechargeable batteries. I would argue that the lease price is not outrageous because it is effectively about $90/month, which includes a year of visits worth about $500, and there’s no way to know what the lease price will be in 3 years.
(post withdrawn by author, will be automatically deleted in 24 hours unless flagged)
2 Likes
I’m going to try to address some of the questions and issues brought up in the last couple of days. It’ll probably take a couple of posts. During my last programming adjustment for the Mores I thought I heard my audi (and the Oticon rep who was participating by phone) say that More Sound Booster was set to be on all the time. I could easily be mistaken.