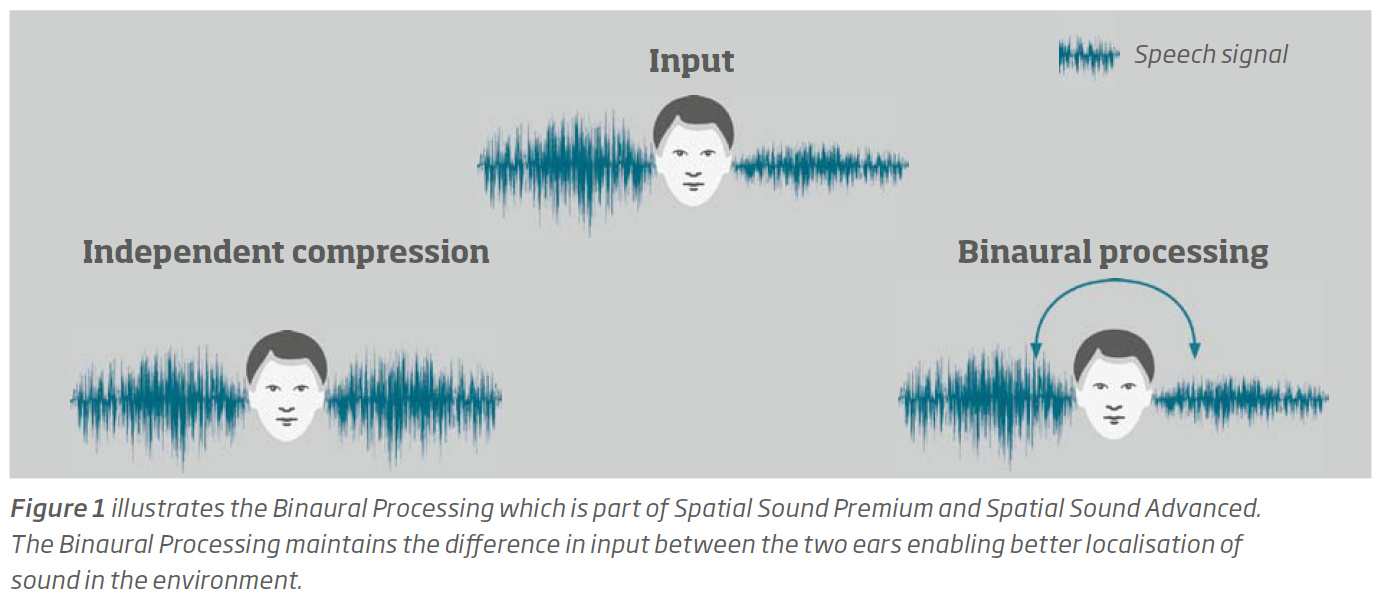
Sure, basically HAs use compression to help you hear softer sounds louder (through more amplification), but louder sounds not as loud (through less amplification), because generally if louder sounds are already more audible to you, there’s no need to amplify them as much as the softer (harder to hear) sounds need to be amplified.
If you wear 2 HAs that don’t talk to each other, the compression is independent. So if you look at the first screenshot below, you’ll see an example where the sound is coming from the right of the listener, so with no HA, you hear a louder sound on your right ear and a softer sound on your left ear (the person on the top). If you wear hearing aids that don’t talk to each other, the softer sound on the left ear gets amplified more (because of how compression works) and ends up sounding just as loud as the same sound in the right ear, which doesn’t get amplified as much (again, because of how compression works). This situation is shown in the person on the lower left. Because of this, you lose the sense of directionality because the HAs amplify the sound to the same level on both sides.
But if the HAs talk to each other (the binaural processing case in the lower right), the left HA will know that the right HA has a louder level sound, and vice versa, so the left HA uses this knowledge to not amplify its left side sound too much, so that a volume level difference between the two is maintained (it’s called ILD for Interaural Level Differences). This way, the user gets the cue that the sound must be coming from his right side. On the other hand, the person with independent compression (2 HAs don’t talk to each other) in the lower left gets no clue where the sound comes from because there’s no volume difference between the 2 HAs.
However, the volume levels between the 2 sides may differ over a range of frequency, depending on the type of sound. The 2nd screenshot illustrates this, with the pink level (on the right graph) being what arrives at the right ear (and it almost matches to the original sound level in the left graph), and the white level there being what arrives at the left ear, at a lower volume because it has to travel a further distance to get there. It also gives an example of a sound that has a higher difference in volume level at the higher end of the frequency range, but less difference in volume levels at the lower range.
The Estimator is an algorithm that is designed to determine what the best estimate of the overall volume level difference is. I’m not sure what the algorithm does, maybe it’s to calculate the largest difference between the left and right volume through out the frequency range, or maybe the median difference, or maybe something in between. But nevertheless, if there’s only one Estimator for the whole frequency range, then there would be only 1 overall compression difference (or compression “scheme”) applied between the left and right HAs across all frequencies.
But if you slice this frequency range into 4 separately equal bands, then you can have a different estimator for each of the 4 bands, and now you can apply 4 separate compression “schemes” between the left and right HAs in the 4 frequency bands, as seen in the second screenshot. The estimators here are the 4 black vertical lines that represent the overall volume differences (ILD for Interaural Level Differences) between the right and left HAs in each of the 4 frequency bands.
This should help you get even better and more accurate spatial cues because the precision of the estimators goes from being very crude with only 1 estimator for the entire frequency range, to being much more refined with 4 estimators for each of the 4 frequency ranges, resulting in 4 independent compression schemes applied in the 4 equally distributed frequency bands.

 will provide me with More3s at no cost, I had to pay an additional $1,500 to get to the More1s. More2s would have cost me significantly less. I still don’t know/understand whether More2s would have done the job.
will provide me with More3s at no cost, I had to pay an additional $1,500 to get to the More1s. More2s would have cost me significantly less. I still don’t know/understand whether More2s would have done the job.