I always think that the Directionality Settings in the Oticon Genie 2 software is kind of a parody to the Directionality Settings in other hearing aid brands’ softwares. That is because most other hearing aid brands actually use the traditional beam forming approach where they use the 4 mics (2 on each hearing aid for the RIC type aid at least) to manipulate the cardioid field to zoom in exactly to where they want to pick up the sounds in that area of interest. On the other hand, because of the open paradigm, Oticon manipulate their 4 mics to do beamforming in a different way, not necessarily to zoom into certain areas to pick up the sounds there and ignore the rest like how the other aids do it (because that would be counterproductive to their open paradigm), but actually to create a noise model and to use this noise model to apply a different kind of beamforming (called MVDR) to attenuate well placed noise sources → thereby “balance” the sound scene to let all other sounds (speech included) that are not well placed noise sources to have an increased presence, and then use a secondary noise remover like the DNN to go one step further and enhance the clarity of the voices.
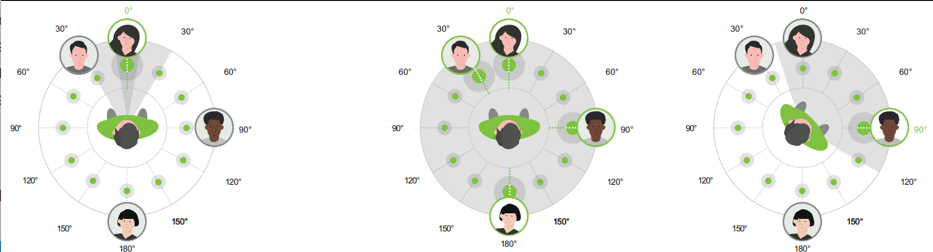
For example, the screenshot below of the Phonak speech sensor shows how their speech sensor detects where the voices come from, then create a forwarding cardioid pattern to pick up sounds that can be very narrow (the left scene), or wider (the right scene), or 360 degrees wide / omnidirectional (the middle scene).
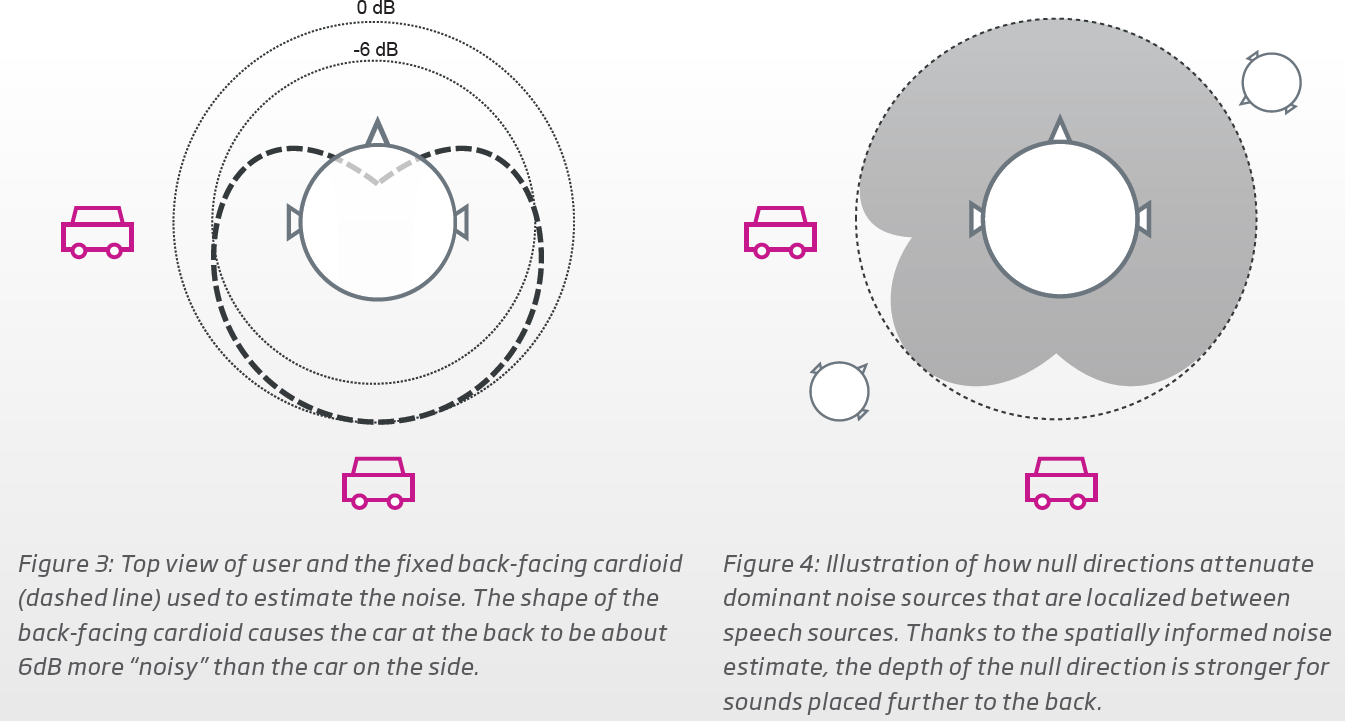
In contrast, Oticon use their 2 mics on each aid to create 2 different views → the first view is an omnidirectional beam that picks up all sounds (to support their open paradigm), and the second view is a back-facing cardioid pattern that picks up the side and rear sounds, which are normally considered “noise”, to make a noise model out of this view. Figure 3 of this screenshot below shows this. Then, to balance out the sound field, they use a beamforming technique called the Minimum-Variance Distortion-less Response (MVDR) algorithm to subtract well placed dominant noise sources (the cars in this example) that are found in both the back-cardioid noise model view and the omni view, to come up with a “balanced” view, which is the gray pattern in the Figure 4 of the screenshot below. Note that noise sources from the back get attenuated more aggressively than noise sources from the side, by design. This balanced view is now put through a secondary noise removal module to scrub the same noise model from the front speeches in particular. If there are voices detected on the sides or rear, then this front-speech noise scrubbing is cancelled to preserve the integrity of the non-front speeches. But this is only in the OPN/S. For the More onward, the DNN allows the noise suppression on the speeches to be done in a much more clever way without the compromise mentioned above for the OPN/S if rear or side voices are detected.
So perhaps by now you can see why I think that the Oticon way of doing beamforming (the MVDR way) is a parody (quite different) compared to the other aids’ brands’ traditional beamforming way. Oticon doesn’t really zoom in to pick up the sounds in the desired/focus area and thereby block out the rest. Instead, Oticon zooms in on only well placed dominant noises to attenuate them first to rebalance the sound scene, thereby being able to keep most other sounds that aren’t dominant noise sources in accordance to the open paradigm, then “polish up” the speeches further in the DNN to wrap it up.
So while Oticon gives you a Fixed Omni and a Fully Directional option, the question is "Does Oticon REALLY revert back to the REAL omnidirectional pattern or the REAL fully directional pattern like the other brands do, or does it try to “emulate” it somehow in some way inside of their DNN because their path to processing the sounds has been designed to flow in a different and set way already?
If they really “reroute” the data through a different path for Fixed Omni or a Fully Directional selections, then why do many people (me included) not notice much difference in terms of non-speech sound blocking when they use the SIN program or the MoreSound Booster? Perhaps their Fully Directional execution is just to “fake” it by giving more SNR contrast than normal for front speeches to give the illusion of having the traditional Fully Directional effect? As for Fixed Omni, if they’re just emulating it instead of really open up the cardioid field on the mics to 360 degrees, then maybe they’re just keeping the sound scene “as is” and not apply any SNR contrast to anything to give the illusion of a wide open sound scene?
All I know is that Oticon offer a Neural Automatic option and suggest that people use this in the main program, and if Fully Directional or Fixed Omni is chosen, then put it in a secondary program. So the implication is pretty clear that → 1) the directionality is manipulated in the DNN (hence the choice of the word Neural), 2) let the hearing aids choose how to set it because it knows best on how to get the best sounding experience out of the DNN, as suggested in their online help captured in the screenshot below.
The bottom line answer to your question is that I wouldn’t try too hard to make sense of why you’re not hearing what you’re expecting in accordance to the directionality setting that you choose, based on your understanding of how it should work, when it comes to Oticon aids. It’s probably best to experiment with both, and if your choice of the directionality setting doesn’t work well as you expect it to, or it seems to work the same as Neural Automatic, or if you still get a better result with Neural Automatic regardless, then it’s probably best to leave it in Neural Automatic and let the aids choose the directionality for you, simply because the aids don’t work in a conventional way anyway, when it comes to directionality in the first place.





 .
.

 I’ve experimented with both ends of neural noise suppression (6dB and 12dB) and found that I understand speech better with less NSS. My lecture program is set with Genie’s recommended NSS target of 6 dB, and combined with its boost in mid frequencies, it provides extra clarity and speech comprehension. However, my P1 program handles noise decently enough that I rarely feel the need to switch programs (P1 is set with 8 dB NSS). I still haven’t compared both lecture and speech in noise programs set with 6 dB NSS though - I wish I had an extra 2 or 3 slots to streamline these tests
I’ve experimented with both ends of neural noise suppression (6dB and 12dB) and found that I understand speech better with less NSS. My lecture program is set with Genie’s recommended NSS target of 6 dB, and combined with its boost in mid frequencies, it provides extra clarity and speech comprehension. However, my P1 program handles noise decently enough that I rarely feel the need to switch programs (P1 is set with 8 dB NSS). I still haven’t compared both lecture and speech in noise programs set with 6 dB NSS though - I wish I had an extra 2 or 3 slots to streamline these tests