I’ve frequently read that frequency lowering helps one hear s and sh sounds if one has a high frequency loss. Upon further reading and looking at the speech banana, I think this isn’t quite right. Frequency lowering should help one hear the f, th and s sounds, and if adjusted properly, it should let you distinguish the s sound from the sh sound. If the high frequencies are compressed into too small a frequency range, one may confuse the s and sh sounds.
2 Likes
In theory what you said may be all proper academically. But in practice, with my personal experience, the “s” and “sh” sounds jump out to me most prominentlly.
The “f” and “th” sound may be up there in the speech banana and all that, but if you think about it, you can still not hear them real well and still be able to guess easily which words that contain them are. At least to me, that’s how it is. So the ability to hear those sounds well via frequency lowering is not important to me because I rarely miss any word that contains the “f” or “th” sound. So even if frequency lowering helps me hear them better, that’s fine but I never had the impression that “Wow, I can hear them now!”
The “s” word on the other hand is prevalent in the English language especially for plural nouns and third person verbs. They’re at the tail end of the words and if you can’t hear the “s” at the end then you wouldn’t know if the word is in the plural sense or not.
As far as the “sh” sound, it sounds very similar to the “s” sound to me except there’s the “h” component in it as well.
That’s why as soon as I tried out the OPN Speech Rescue, I went “Wow, I can hear them now!”
Then you gotta consider where the ski slope drops off and it’s different for different individuals. So the frequency lowering cut off point is all different so one person’s experience may not be the same as another in the first place. So there’s no right or wrong way to do frequency lowering as long as it’s effective and helpful for that individual then it’s all good.
Also, regarding how compressing a wider bandwidth in the high end and fitting it into a narrower lower frequency band can be effective, I’ve read that actually the frequency bands selection of the OPN speech rescue is based on the natural logarithmic scale of the hearing bands as perceived by the human ear, so the compression into the tighter lower bands is actually very natural to the way human hears. You can look up the Speech Rescue white paper by Oticon and they will explain it in more details in there.
So as far as the “s” and “sh” sounds in the tighter lower frequency bands in the OPN Speech Rescue, I don’t get confused between them despite them being in the tighter lower band.
But do note that the Speech Rescue technology is not frequency compression, it’s transposition and composition instead, and it also leaves the original higher frequency sounds intact. So I don’t really know if my experience would have been the same if I had used something with frequency compression or not.
1 Like
I think we may be talking past oneanother a bit and I likely was not terribly clear. I’m glad Speech Rescue works for you and that you don’t have any difficulty differentiating the s and sh sounds.
In the literature, the way that frequency lowering is often evaluated is seeing if it made the “s” sound audible. If so, it is also checked to make sure patient can distinguish between between the “s” and “sh” sound. “F” and “TH” sounds were mentioned because of their location on speech banana and I can hear them better with frequency compression. If Speech Rescue makes “sh” audible and it isn’t without, I’m guessing it’s making a lot of other sounds audible too.
Although Speech Rescue is not speech compression, it does still “squish” the frequencies together. Perhaps they avoid “s” and “sh” confusion by use of the logarithmic scale.
And yes, quite familiar with the article on Speech Rescue. I believe I showed it to you sometime back and quite a discussion ensued.
What happens to music? I don’t mean specifically music listening, but more like in a movie or tv show.
Not really. While other frequency lowering technologies actually compresses the higher frequencies into the lowered frequencies, causing distortion, Speech Rescue doesn’t do that.
Let’s take the configuration 5 of the chart below where the audible range is between around 2.5-3.5 HKz, which is the destination region. And the lowered region is between around 5-8 KHz.
With other frequency lowering techniques using compression, the range of 2.5-8 KHz would have been squished between the target of 2.5-3.5 KHz. So not only all the sounds between the non-audible region of 5-8 got squished, even the audible sounds betwee 2.5-3.5 get squished as well. This results in pretty bad distortion of sounds throughout the whole range, INCLUDING sounds in the audible range which shouldn’t get distorted but getting distorted anyway as well.
The Speech Rescue lowering example below doesn’t compress anything. It divides the 5-8 KHz range into 3 sections, roughly 1 KHz range per section, then transposed each of the 3 sections into the 2.5-3.5 range and compose the 3 sections on top of each other. So there’s no compression because a 1KHz section of the highs gets imposed to roughly the same 1KHz range on top of the lowered section.
On top of all this, all the sounds of the 5-8KHz range are preserved exactly as is, so you don’t lose any sounds, you only get MORE/EXTRA lowered sounds, that’s all.
The squishing of Speech Rescue into the lowered region based on the logarithmic scale is not about compression and squishing, but as you can see in the example of the 10 configurations below, is about being able to divide into 3 sections and transpose to a lower range, and compose the 3 sections on top of one another onto the lowered sections. I think what Oticon is saying is that the natural hearing based on the logarithmic scale allows Oticon to based on this scale and make a decision on how to section out the upper (and wider) range into the lowered (and narrower range), and still enable the lowered sounds to sound the most natural, even if the higher sounds are sectioned out into 3 parts and superimposed on top of each other into the lowered range.
So technically there’s no “squishing” in Speech Rescue per se like with other frequency lowering compression technologies. The only squishing here is more like sectioning out into 3 parts and superimpose them into one same lowered section. The name of the game is here to minimize distortion. Preservation of the original high frequency sounds also helps minimized any distortion, that is, if you can also hear the amplified high frequency sounds as well.
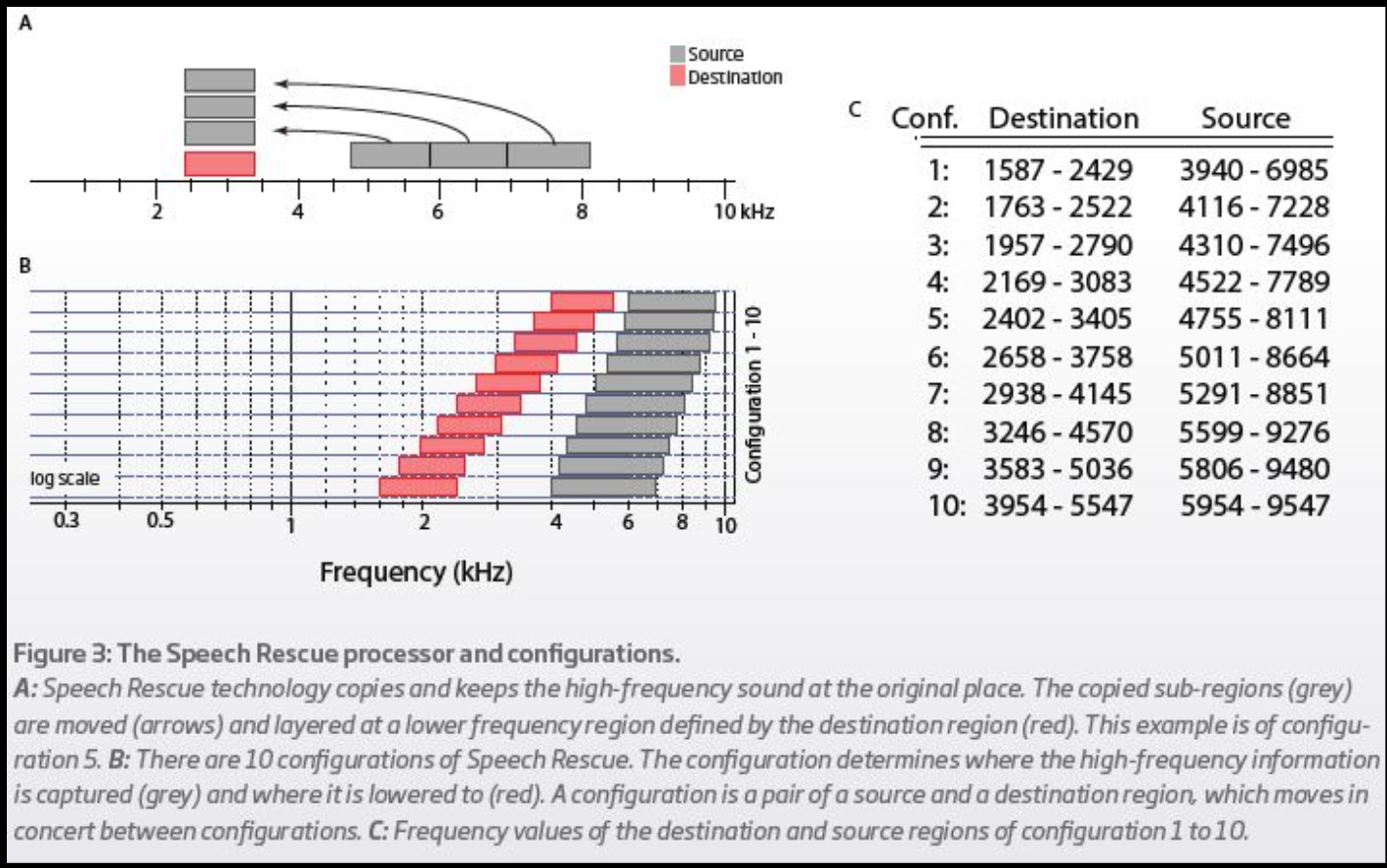
In setting 1 from the chart, the source region is 3940-6985 is a range of 3045hz. If it’s split into 3 equal sections, that’s a range of 1015hz. That 1015 hz range is then placed on top of the 1587-2429 hz range which is 842 hz. So it seems a range of 1015 hz is “squished” into a range of 842 hz.
All frequency lowering schemes create distortion. Oticon’s creates distortion by placing sounds on top of already existing sounds and a little bit by compressing them. So in the range of 1587-2429 hz, there is the existing sound and then the higher frequency sounds are overlayed on top of that area.
And to reply to the question about music. It gets lowered and distorted too, so if one wants music to sound good, one will likely not like frequency lowering. Not always true, but if anybody with normal hearing tried using frequency lowering, it would sound awful.
Compressing from 1015 Hz into 842 Hz is NOTHING compared to compressing a 3 KHz range into an 842 Hz range. In theory, compressing 1010 KHz into 1000 KHz is still considered distortion, but can you really tell this 1% distortion?
By the way, the choice of compressing from 1015 Hz into 842 Hz is not due to any limitation, but is by choice, based on the natural selectivity of the hearing cochlear, to make the best fit into the natural range where the hearing can utilize sounds the best. So if introducing this 20% distortion on purpose is far outweighed by the benefit of being able to squeeze the sounds into the most optimal hearing range, then it’s a calculated decision that still yields the most benefit.
The high frequency sounds overlayed on top of the existing sounds may be considered distortion in theory, if by definition, distortion is anything different than the original sound. But you also have to consider that the layered sounds have different characteristics, and the human ear can most likely discern the differences between the sounds and is able to differentiate them, even if they are layered onto the same region. After all, if the human ear can discern multiple voices speaking simultaneously to focus on one voice and tune out other voices, I’m sure it’s not difficult for the human ear to discern the difference between a lowered sound against other normal sounds that exist in the lowered region.
Also consider that the lowered sounds most usually probably don’t appear simultaneously with the regular sounds in the lowered region, making the distinction even more easy and distortion a non-issue. It’s kinda like creating a mixer and adding new sounds to the original sounds. Adding new sounds on top is not the same as distorting the original sounds.
I personally can discern this difference easily and don’t have any problem because the lowered sounds don’t take away meaningful information (which to me is what distortion really is in practice) of the regular sounds in this lowered region.
Another thing to mention is that you have complete control of the lowered sound in terms of regulating the lowered sounds volume in Speech Rescue. So if you feel that the lowered sounds are too loud and take away your ability to hear the regular sounds in that lowered region, simply reduce its volume to have a well balanced soundscape.
As far as frequency lowering technology making music listening sounding awful, again, in theory that may be the academic assumption. But pleasantly surprising in practice to me personally, I have Speech Rescue enabled in my default program, and listening music to me in this default program still sounds just the same to me, if not even a little more enriching in fact. Your mileage may vary, but that is my personal experience with Speech Rescue when listening to music. And while I’m not a professional musician, I consider myself knowledgeable in music, can carry a tune, and can tell if the music is out of tune or distorted and sounding awful.
But when you think about it, the lowered sounds probably don’t carry enough energy to constitute a tune anyway. It’s probably mostly the timbres of cymbals and other high frequencies things like transients and resonants that color and add on to the music and not necessarily making up the core of the tune anyway. So they wouldn’t necessarily make the music sound out of tune in the first place.
Again, do note that this is my experience with the Oticon Speech Rescue technology. I can’t speak for other frequency lowering compression technologies as I think that may yield different results than with the Speech Rescue technology.
With Speech Rescue In movies or TV shows, the speech is enhanced with the lowered sounds for me, and the music in them sounds just fine to me.
I’ve come to the conclusion that nobody else cares about this discussion.
I think our biggest disagreement is how we use words. I think I’m more picky.
You said the Opns didn’t compress at all. I said they did and demonstrated it. I agree that they don’t do it near as much as true “compression”.
Just relooked at the white paper you referenced. It mentions the s, th and f sounds early on and on page 7 mentions that one may need to alter the strength to avoid confusion between s and sh sounds.
2 Likes
While transposition sounds good in theory, limited independent studies suggest that users do better with compression than with transposition. Mind you, there is no independent verification of Oticon’s current strategy at this time, so who knows.
3 Likes
I certainly prefer the term transposition. At least that describes what’s going on (for freq lowering at least).
1 Like
The Connexx software recommends FCo for my Universal program. It was originally set at 2.0 - 3.5, which made my wife sound like she had a lisp. I moved it to 2.5 - 4.0 and that helped. I have tried it off and on and I think I hear the tweety birds better with it. Not sure about speech, but it does not seem to hurt. I do not use it on the TV or Music programs. I probably should play around a little more as there does not appear to be any science here. Look at my audiogram and give me you thoughts. Thanks.
Here’s a link to a good course form Audiology online.
You’ll need to register with them to view it, but there is no cost unless you want CEU credits. Fitting frequency compression is a lot of trial and error. Ideally one starts off knowing what one’s maximum output frequency is (maximum frequency that you can hear with around a 65dB input) You’ll need REM testing to determine it accurately. Start frequency should be below MAOF. Sounds like you’ve found something that’s helpful. In the adjusting I’ve done with mine, I’ve found things initially sound sibilant (like your wife’s lisp), but after awhile it sounds “normal.” I started off with recommended settings of 5-7 and have ended up at 3.5-5, although in my oudtoor program I used 3.25-4.5 which really helps with the birds. If you wanted to try a little stronger, I’d try 2.5-3.75. I can supply a lot of other references if this is something you’d like to dig into deeper.
1 Like
Wow, that info is why I use this forum. I have no way to do REM, so it is trial and error. I will do the online and also try narrowing the FCo. The Connexx software has suggestions, but there is no absolute answer. I think the lisp from my wife were some sound I had not heard before. I may have indeed gotten used to them, but took the easy way out. I originally had a duplicate Universal program without FCo that I could compare. That was useful and led me to use the FCo in the first place.
I notice your curves drop off much steeper than mine and as I understand it that makes FCo more beneficial. Thanks for the help.
I did read this paper:
Thank you folks… rather interesting thread for me at least as I am planning a set of OPNS 1 later in the year and speech rescue seems much more appealing now, given my level of loss in the severe to profound threshold, I don’t expect it to be perfect, but every little glint of contextual information can only be a bonus  might not work for me given my level of loss though? thank you again, cheers Kev.
might not work for me given my level of loss though? thank you again, cheers Kev.
That paper is a good intro. There are several others that give good information on the different forms of frequency lowering. The one I linked is specific to non linear frequency compression and is targeted at Signia hearing aids, so helpful with any aids that use Connexx. I think my loss is well suited to using it. One thing to keep in mind since your self fitting is what fitting formula you used and did you make any adjustments to the highs.
I have only used the NX fitting as an experienced user and tend to lower MPO above 2.5. I am pretty happy with one on one speech and even music. Noise is still not resolved. I tend to deal with it using directional mics and volume.
Since I don’t have REM, I use an over the ear headphone and run an audiogram, which may not be calibrated, but it does show relative benefit of FCo in the 2.5 - 5 range.
Good that you’ve got it set to experienced user. Definitely sounds like you’re in the ballpark.
Thank you guys for the useful info you provide. I’m already very profoundly deaf with no hearing after 1000 Hz in the right ear and after 2000 Hz in the left with little residual hearing at 4000 Hz. Added the audiogram to my profile.
I’m going to buy a new set of HA and narrowed my choice to Oticon Xceed UP and Resound Enzo Q. Both are very good aids but as I have no hearing in the high frequencies its very important for me to pick the aid with the frequency lowering technology that will work best for my case…if even work. Resound’s Sound Shaper rely on frequency compression algorithm with compression ratio 2:1. On the other hand the Oticon’s Speech Rescue rely on transposition and composition with much lower compression. Resound’s technology offers pretty basis options for frequency lowering with Mild, Moderate and Strong options with cut-off frequency at 2500 Hz for Strong. I have no info about the options for Speech Rescue in the Oticon’s Genie software.
Since my ski slope ends at 1000 Hz for the right ear and 2000 Hz for the left it’s not possible to compress the whole high frequency range and a lot of high frequency hearing need to be sacrificed. If the audible range for “th”, “s”, “sh”, “f” (4000-5000 Hz) can be successfully lowered I would be happy with the result because speech audibility is most important for me. I need you to give me advice which technology would work best for my case. I would consider other manufacturers too if their solution is best for my very severe case.