I have looked through the threads on Whisper and tried to assimilate its learning paradigm. What I am missing, and it seems significant, is how the Brain/Hearing Aid determines if the calculated adjustments to the sound output to my ear are better or not. Without that feedback how can the system determine an improvement path? If you wear corrective lenses you are familiar with the drill where two lens are flipped into the field of view and the patient is asked which is better. First or second. I give feedback. Incremental improvement. Where is that step in the the Whisper approach with the end user?
Whisper doesn’t do that. Their innovation, unique in the industry and IMO very real and promising, is use of an external processor, faster and with more memory than behind-the-ear hearing aid processors, to enhance their aids’ sound processing capability.
1 Like
The feedback loop is you saying to your audiologist, “when I’m in thus and such a situation, it sounds bad like this,” and they tweak your programming, and you go out again. It isn’t like an app where you can dynamically shape things. This is pretty much the case across the boards unless you are into DIY.
WH
Once again there appears to be no magic. I suspect that the processing of the environment done in the ‘Brain’ builds a better digital representation that could be used by the audiologist to tweak settings—but no magic. And no loop to speak of. I interpreted continuously evolving adaptation as a closed loop system. I was too optimistic. And the lack of a closed loop is what prompted my original question. To close the loop you must use our present day chat with the audiologist to chase improvements. A technique fraught with variables as we all know. Thanks for the replies.
Yes, AI can’t hear what you are hearing. A true feedback loop would somehow tap into your own hearing experience in the world and other hearing situations and make adjustments–learn, as they say. But the “Brain” can’t do that. It’s not YOUR brain; or rather, your ears hearing the world. It’s computer chips programmed with algorithms. It can’t hear, it’s deaf, so to speak.
So it may be back to square one: like any other aid, it needs input from you to be programmed correctly. I suppose one could say that any programmable aid is ‘smart’ and ‘learns’ in this way.
Yes, Jeffrey, your assessment matches my take after thinking about the replies. It would not be terribly difficult to built a hearing aid ‘persona’ that could interrogate the user to gain a thumbs up or down on proposed processing changes. Making it effective but not intrusive might be tricky because everyone is so different. I do believe such is coming and rapidly. In many ways this the golden age of hearing assistance and we ‘ain’t seen nothing yet.’
Ciao
Actually, most of the major HA manufacturers have smartphone apps that essentially do that, perhaps awkwardly, in creating “programs.” It’s a starting point.
I agree. Though I admit a bit of tunnel vision as I never looked at it in that way. My own small attempts at customization have not been proud moments. More like flailing acts of desperation.
@VinceJ Do you mean you’d like the AI processing to be individualised for you? The first question I’d ask is does it really matter? Is the processor’s job of isolating voices in a sound scene going to be different for you and for me? You’d need to have some understanding of what parameters the AI system can adjust to optimise the user experience. Personally I have no idea. If the answer is yes the follow-up question is how long are you prepared to wait for this to happen?
If you’re looking for an AI hearing aid setup that incorporates A/B comparison feedback from the users, try Google the Widex SoundSense Learn and Made For You and Made By You setup. Below is the link toan article and some snippet from it.
The AI training approach used by Oticon and Philips and probably Whisper as well is done in the labs and called supervised training. They present a large amount of data points collected in real life and feed the data through the AI system and observe to result, then compare the result against the referenced (golden) expected output to see how well they match up. Discrepancies found get propagated back into the system for tweaking to continue to try to minimize the discrepancies. After enough data points get fed through and enough tweaking is done, the system gets good enough for production release. But no further enhancement is done on the fly in real life. If they do any further training or improvement, it’d be done in their labs for a future release. But the released version is “as is” and doesn’t get better on-the-fly.
The other approach, unsupervised learning, would collect more data from on the fly real life situations as experienced by the users and try to improve the system continuously with this new data. A variation of it is to collect inputs from users in A/B comparisons to feed that back into the system to continuously enhance it. It seems like Widex does this user-input A/B comparison to enhance their AI setup from inputs of their users world-wide.
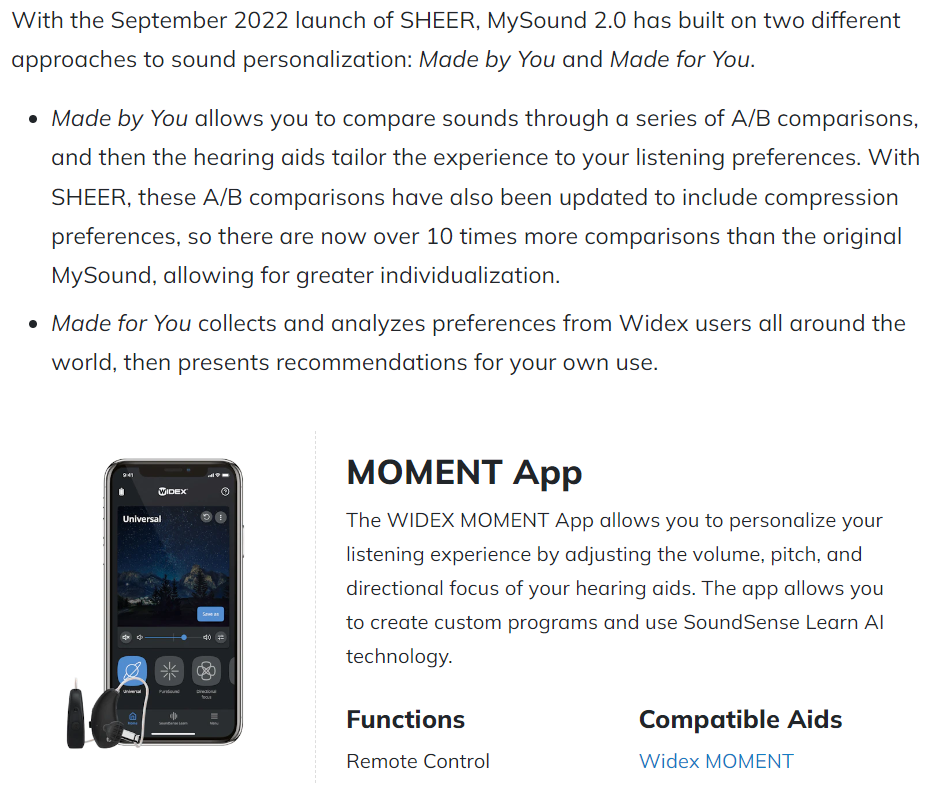
2 Likes
d_Wooluf: Yes, you are correct. I am thinking that ultimately the tuning should be individualized. This increases the challenge of course but our minds interpret the data stream from our sensors (ears, etc.) in peculiar ways. Individual ways.
Volusiano: The Widex item is striking. I have lived in the Oticon/Phonak camp heretofore and never gave much thought to Widex which I considered an outlier. What they term “Made by You” is intriguing. I need to invest some time to learn a bit more. The more I learn the more obvious it is that I might have underestimated the challenge. And just when I thought I would ride the Phonak horse into the boneyard.
I look at the apps as analogous to cutting your toenails with an axe compared to what can be done in most of the fitting programs our HCPs use (or DIYers)
WH