Here is a very interesting paper from Phonak on artificial intelligence using machine learning (ML) vs deep neural networks (DNN) with regards to hearing aids.
Obviously a shot at Oticon’s use of the DNN approach in its sales literature. I though the article was well written, understandable and informative. I had just completed reading the 6 or 7 Oticon White Papers relating to its DNN and I found the Phonak paper to be a relief. The Oticon papers, although containing much information, were definitely sales pieces, although I was not sure who they were directed to. The Oticon papers are written in a very pedantic style. It is almost like some editor looked at them and said, we can use bigger words here, make non engineers run to their dictionaries and make the sentences a little longer all to sound more scientific and impressive. Quite honestly it took me a couple of days off and on to get through them and in the end I was exhausted. I thought that the Phonak paper was written in simple business English with a positive approach. As a retired financial/accounting/risk person with little knowledge of current AI concepts I thought it was educational. As to which approach is best, I am waiting for the Philips 9050 from Costco to compare it with my Phonak L90s.
In interest of increasing the discussion and to provide additional input on subject - I have changed the Topic Title. My enthusiasm in this topic is due to the revolutionary changes that I believe are coming to hearing aids and other listening devices such as ear buds, etc.
First, I will provide a hopefully brief input of my interpretation of the Phonak Insight paper. I will limit my discussion to the DNN or noise reduction portion of the paper as I believe this is the area for greatest improvement in HA technology. Hearing aid technology has primarily focused on sound amplification and noise reduction as methods to improve speech intelligibility. However, the problem still remains that people still find it difficult to understand speech in situations with background noise. Hearing aids use directional mics “beamforming” to spatially improve speech understanding in a frontal direction while simultaneously reducing noise from the side and backwards directions. Resulting in a speech understanding or signal-to-noise ratio (SNR) improvement of approximately 4-8 dB, depending on a variety of factors. In comparable situations AI using DNN has the potential to provide a SNR improvement of 12 dB or greater (Phonak paper and references therein).
My interpretation of Phonak paper:
I was hoping that Phonak was going to release a new HA this year that included some form of AI for noise reduction. I now believe that it will take longer (at least one to two years maybe more) before this will happen. I believe that the paper stating that “DNN-based denoising technology offers a potential that current hearing aids do not have access to yet” indicates this.
Oticon and others have shown that HA are currently capable of DNN-based noise reduction (AJA 2023 - Evaluating Real-World Benefits of Hearing Aids with DNN-Based Noise Reduction).
My limited research has identified at least three companies that are or are on the verge of providing hearing devices with DNN-based noise reduction. These include: 1) Femtosense in US, 2) GreenWaves in France, and 3) Alango in Israel. Another one was Whisper which suddenly ended their product for some reason - does anyone know why this was the case or if the technology has been taken up by some other company?
Another important implication is that DNN-based noise reduction provides the ability to provide improvements in speech intelligibility for mild-moderately impaired individuals that is on par with normal hearing and could be used to improve speech understanding for normal hearing listeners in noisy environments such as crowded restaurants or bars. This would be available in all hearing devices including ear buds etc. for a very low cost (hundreds of dollars or less).
I have severe hearing loss and i have the More1 and Real1 aids both sets have greatly improved my speech understanding. I am looking forward to getting the INTENT1 aids in about 6 weeks. For me I wasn’t expecting the improvement I got from the More1 to Real1 aids. My VA audiologist believes that I will see even greater improvement with the INTENT1 aids. I am someone that can hear people talked even without my aids but it for the most part sounds like a foreign language. Music is something I have no hope of ever enjoying again. My wife always talks about how beautiful or church choir is but I just hear noise and the piano playing out of tune. I can enjoy the sermon due to the loop system and t-coils in my aids. But for some reason the t-coils don’t help me understand the song lyrics.
First of all, I’d like to ask the OP (@TimMac ) to elaborate on the choice of the work “reckless speculation AI”. Who is speculating recklessly about AI in particular? The HA mfgs? The users? And how is it reckless to begin with?
Secondly, I agree with @raylock1 that this Phonak paper is written more for the layman to understand more easily, compared to the Oticon papers. However, I wouldn’t say that the Oticon papers are written in a pedantic style. But I agree that they’re definitely not written with the laymen in mind. I think they’re written more for technical people (engineers like me, for example), and HCPs who are very familiar with a lot of the buzzwords they use in the field of audiology. From that angle, they’re not trying to use bigger words unnecessarily, I just think that the language used in engineering is usually very succinct and precise, with a lot of technical jargons that are uncommon to non-technical folks.
Four personal observations that I get out of this paper:
Phonak seems to want to make a point that the classical noise cancellers in modern HAs (as illustrated in Figure 3, and in the text, namely the beamforming technology) are always more efficient than any DNN IF the same amount of resources (parameters as they call it) is required compared to what the classical noise cancellers use. But it does concede that if more parameters can be afforded to the DNN, the DNN eventually can outperform the classical noise cancellers.
The Phonak paper makes a distinction between ML (Machine Learing) and DNN (they call it “deep” learning sometimes). On page 4, in the third paragraph of its Sound Scene Classification, it says that many HA mfgs, Phonak included, have used ML instead of DNN deep learning for sound scene classification tasks (using its AutoSense OS) because ML is already very good at doing this, without needing to resort to the more compute resource intensive DNN for this.
At the bottom of page 4 and onto page 5, in the section “Speech and Noise Separation”, the Phonak paper explains how it uses AutoSense OS 5.0 to classify the sound scene, then uses beamforming to separate noise from speech. The new thing that Phonak’s Speech Sensor does here, though, is that it no longer just does beamforming for the front, but now can do beamforming to the sides or back, wherever the dominant speech is coming from. However, it acknowledges that beamforming is not perfect, because beamforming cannot separate speech from diffused noise coming from the same direction as speech. On top of that, beamforming, even if it can localized in any direction by Phonak’s Speech Sensor and not just the front, it still cannot address multiple speakers simultaneously speaking from different direction because beamforming is inherently still a narrow focus strategy, regardless of where it focuses (front or back or sides).
In its section “The Future of Speech and Noise Separation” on page 5, the Phonak paper says that the DNN has the potential to solve the problem as explained in part 3 above. with potentially up to a 12 dB SNR noise attenuation. HOWEVER, it claims that current hearing aids DO NOT have access to this potential DNN performance of 12 dB SNR yet.
My shorter summary below:
This Phonak paper does a good job explaining AI, separating the Machine Learning and DNN (Deep Neural Network learning) and explaining ML and DNN in details that is easily understood using mostly laymen terms. It confirms that it uses ML and not DNN for its AutoSense OS 5.0, because ML is good enough for this and DNN would be overkill. It also confirms that it still uses beamforming, albeit not just front beamforming anymore, but “any-directional” beamforming. It acknowledges that beamforming is not perfect for multiple speakers simultaneously talking from different directions. It acknowledges that DNN noise cancellers (as opposed to beamforming which is the classical noise canceller) can solve this problem with up to 12 dB noise attenuation. But it claims that no HA mfg has been able to offer this DNN of up to 12 dB SNR yet because it’d be too compute resource intensive to realize in hardware for now.
My comment:
The Oticon More has already reached the market 3 years ago in 2021, it has a DNN that can do denoising with up to 10 dB. The Oticon Intent, with its second generation DNN 2.0 (recently released earlier this year) also does denoising, but can now deliver up to 12 dB of denoising from the 10 dB with the More and Real. So why is this Phonak paper which is released in 4/2024 claiming that no such hearing aid has yet to reach the market???
Maybe I’m misunderstanding how AI works, but I don’t see how it could ever work well for increasing SNR when the noise is more speech. Human interactions are just too variable. There will be times when the person I want to here is two feet away from me and we’re facing each other. There will be other times when the person I want to hear is farther away than that, and/or in a different direction. Trying to extrapolate One Right Way of increasing SNR from the sum total of my behavior in every prior noisy situation doesn’t seem like it would end well. I’d rather have manual controls via an app.
I haven’t gotten my INTENT1 aids yet but from what i am ready the sensors in the aids should help with that by the aids understanding where you are looking.
You have a very good point here. And it depends on the approach of reducing the noise. I will give a few examples:
Directional beamforming: there has been many research and studies on this, and for frontal beamforming to work, there are a few requirements. The speaker must be within 6 feet in front of you, the room cannot have too much reverb (like with a high ceiling or a huge room), and the noise to be blocked must be on the sides or rear, not coming from the front which is the same direction where the speaker is. If it’s any-direction beamforming, then the same rules would also apply → within 6 feet, room with little reverb, and noise not from the same direction as the speaker.
However, this is a classic denoiser technique, this is not AI.
When you say that if the situation is such that the actual noise is more speech, there is a distinction in audiology because the obvious speech and what they called the “babbles”. Babbles are speeches all around but not really clearly distinguishable (to a speech detector used by a hearing aid), and therefore, babbles are treated as a type of droning (almost machine-like noise) and there are signal processing techniques that can suppress droning noises.
3.a When there are multiple discernable speeches from around you that are not babbles, and specific to AI, it depends on the AI. It’s already been established above that the Phonak AI is machine learning and dedicated to task of environment classification that can lead to some kind of beamforming, so the denoising by Phonak is not using the AI per se, but still using beamforming. But the Phonak AutoSense OS 5.0 can still beamform to somebody facing you or behind you or to your sides to help you focus, as long as it’s one dominant speakers speaking at a time. If it’s multiple speakers simultaneously, then it wouldn’t work as well.
3.b Strictly AI speaking for denoising, one type of AI DNN is like with the Philips hearing aids, where the AI is trained to remove noise from a noisy speech sample. This is not beamforming anymore, this is the DNN cleaning up noise from speech. But if you have multiple speeches (and assuming no other types of noise except for the multiple speeches just to keep things simple and consistent with your case ), then in theory you’ll end up with competing speeches going on around you just the same, but ONLY if those multiple speeches occur simultaneously. Otherwise, if that person is not 2 feet away from you but 6 feet away from you, but not a simultaneous speeches situation, you’ll still hear the 6-feet-away speech just the same, albeit not as loud as the 2-feet-away speech. Same with from behind or on the side.
3.c. The Oticon DNN doesn’t really remove noise from speech in the sense of suppressing everything and only let speech(es) through. Because of its open paradigm, it wants you to hear (almost) everything, not just 100% speech only. Therefore, it’s not about “cleansing” the noise from the speech like with the Philips aids in 3.b above. It’s more about rebalancing the sounds in the sound scene so that (almost) everything can be heard, but some (like speech(es)) can be heard more clearly/louder tha others (like various other non-speech sounds). The Oticon DNN reads in the sound scene and breaks down the individual sound components in that sound scene, then re-assembles these broken down sound components into a newly recreated sound scene.
The difference between this newly created sound scene and the original one (the actual one) is that the “balance” (the volume levels) between the various sound components are “changed” to the way the user specifies. If the user specifies more aggressive noise reduction for speeches, then the non-speech sound components take on a much lower volume compared to the speech sound components. The other thing about these sound components is that they’ve now been rebuilt into discrete sound components, free of having other sounds “diffused” into their own sound. So they’re “cleanly rebuilt” sounds that don’t have to be “cleansed” of noise anymore, because the breakdown and reconstruction process of the sound components kind of 'cleansed" them up already.
Back to your example of simultaneously distinct speeches (not babbles) going on at the same time and competing with each other, how do you remove the “noise” if the “noise” is more speeches, like you asked. Well, you don’t. That is where your brain hearing has to start working to discern how these speeches are different (between male or female speakers, maybe loud or soft speakers, old or young voices, etc), and take advantage of these differences to learn how to separate them out, in order to focus on the speech you want to hear and tune out the speeches you don’t want to hear. That is why Oticon originally talked a lot about the brain hearing when they introduced the open paradigm. Just to be clear, brain hearing is not something Oticon created, it’s just the inherent ability in a person’s biological brain to work on “how” they want to hear and “what” they want to hear. And it’s a very capable biological function that people puts into use everyday.
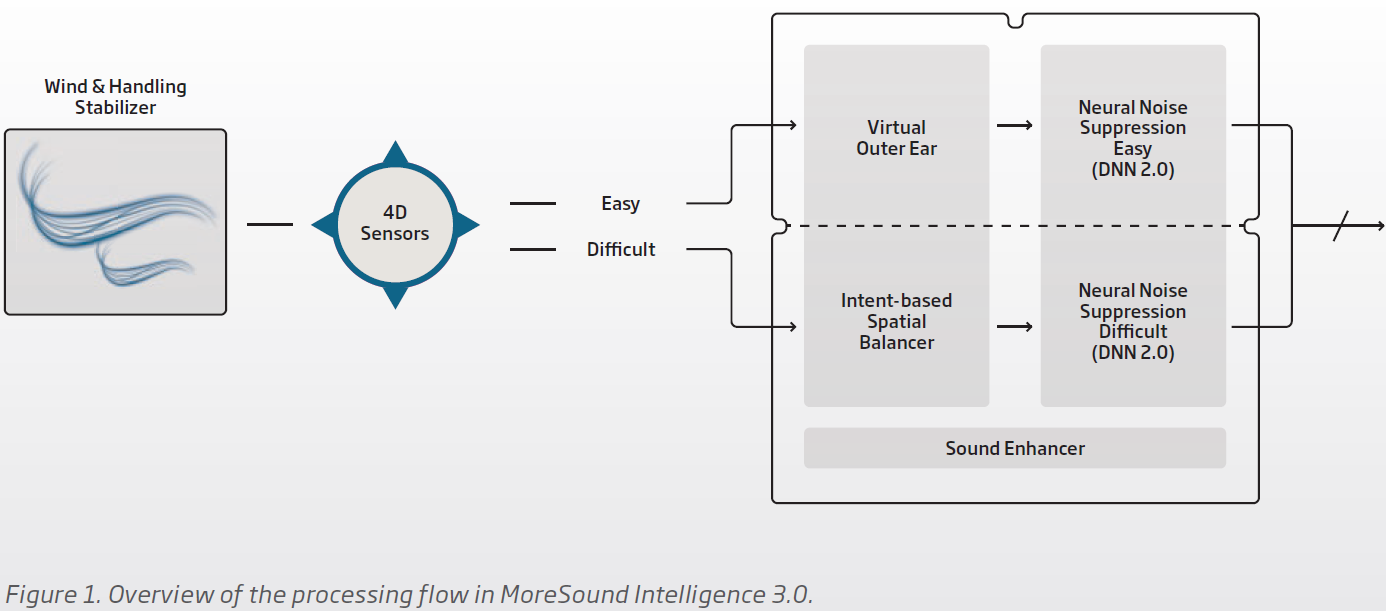
Anyway, with the Intent, they decided to give a little “help” by introducing what they call the 4D Sensors using head movements among other things to help them guess the user’s intent better. Like if the head is not moving, they interpret it as concentrated listening and apply more focus to the front speech. If the head is moving a little bit, then they revert to a default focus to maybe a little wider field. Then if the head if bobbing up and down like when walking, they change the focus to wide open 360 degrees.
Back to your final comment that you’d rather have manual controls via an app. Not sure what you’re referring to here, maybe to change to different built-in programs? Like from General to Speech in Noise, etc? Well, that is not going to help you be able to hear multiple speakers talking simultaneously any better than before anyway. Most Speech in Noise programs is based on front beam forming in the first place. Phonak, starting with their Lumity (latest) model, has designed their AutoSense OS 5.0 to be smart enough to change the parameters for you all in the comfort of the same General program so that you don’t have to even do manual controls for program changes via an app anymore. Oticon has always designed their aids to work in a single General program for most environments as well already, starting with the OPN to the More then Real then Intent.
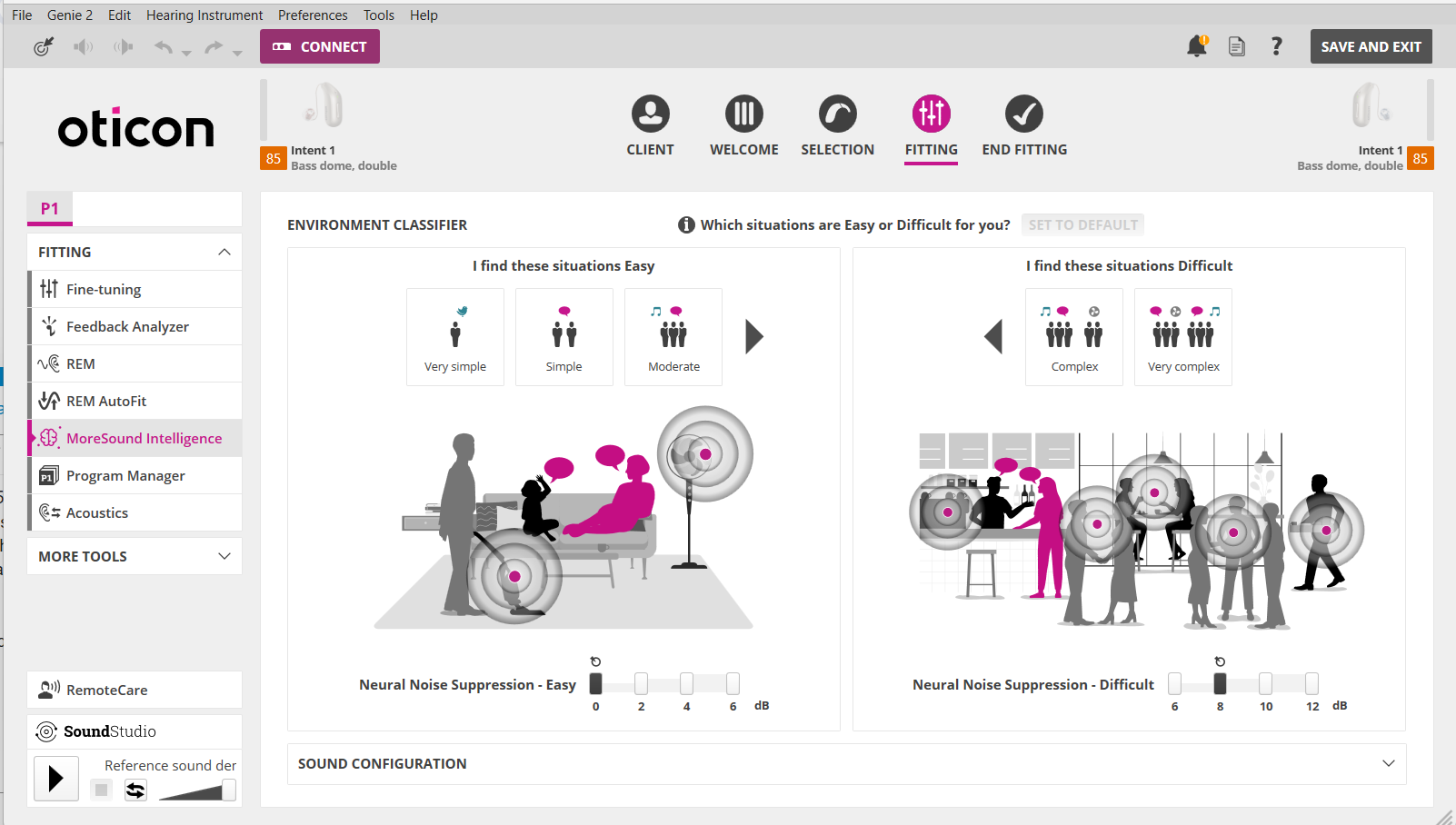
The screenshot below for Genie 2 expressly showed up to 12 dB Neural Noise Suppression in the MoreSound Intelligence for Difficult Environment. The MoreSound Intelligence is the DNN of the More, Real and Intent.
The second screenshot shows where the Neural Noise Suppression for Easy and Difficult are, smack inside of the MoreSound Intelligence 3.0 module.
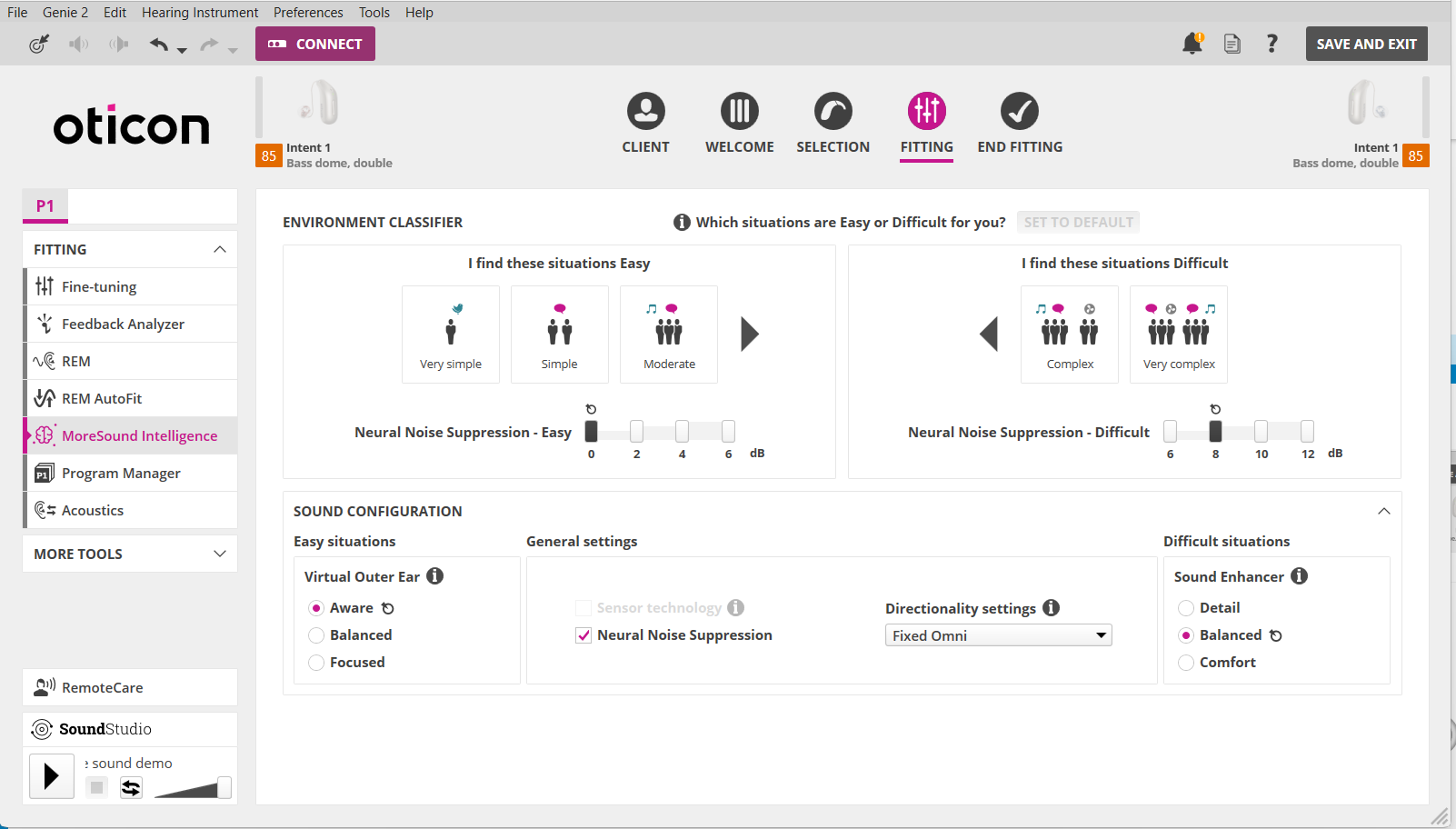
Of course Oticon aids do give a Directionality Settings of “Neural Automatic”, “Full Directional” or “Fixed Omni” as options to customize programs, so one can control the directionality of the aids if they want, or they can let the aids control the directionality automatically as deemed appropriate. So if you want to use this as a technicality to argue that “maybe” directionality contributes to “some” of the noise attenuation, look at the screenshot below. Even if it’s set to “Fixed Omni”, where there’s no directionality, you can still get up to 12 dB in the Neural Noise Suppression just the same.
I used the term “Reckless Speculation” to indicate that my response is in part based why did Phonak write this paper in the first place, which I can only guess at thus the term “Reckless Speculation”. Unfortunately, I got too involved in attempting to summarize the content that I never discussed the purpose. So here is my take on that.
First, the paper presents a somewhat selective literature review of the current state of progress regarding use of DNN-based noise reduction. Inherently, this means that it is outdated with the current state of progress since the published literature is always behind the actual technical advances. I use selective because it appears that Phonak purposely did not want to refer to literature produced by or in regard to Oticon hearing aid products.
Why would Phonak do this? One possibility is that this is a business decision. Phonak may want to delay producing hearing aids with DNN technology to reduce their research costs. They can let the technology be improved by other companies and then implement it once it is a more developed technology thereby reducing the cost to implement. Being the first mover in a disruptive technology can lead to significant advantages but that it not always the case.
Another but less likely possibility is that Phonak is just not ready to provide this technology and needs more time to develop and test it. In the interim they want to maintain their market share and are attempting to do that by persuading audiologists and users that the technology is not quite viable at the present time.
Enough reckless speculation - I am more interested in seeing the technology advance and I would prefer that all players have success and continue to provide competition so that hearing aids improve faster and to hopefully reduce costs.
Thanks for elaborating on your choice of words for the title. It sure is an eye catching choice of words so it peaked my curiosity, that’s all. I now understand where you’re coming from with it now.
I guess the purpose of this Phonak paper is almost as if to justify that its current application of machine learning for its AutoSense OS 5.0 is the right choice over using a DNN of some sort for AI. But it kind of almost prefaces a future enhancement of some sort that is based on DNN, saying that they’re aware that whatever they have right now with the classic denoiser (beamforming) is limiting, and a DNN solution will solve that.
They didn’t outright say that they are working on a DNN solution, but they sure are showing that they fully understand the potential of what a DNN can do as a denoiser over the limitations of the classic beamforming denoiser. It’s almost as if they’re saying “we know all about DNN, here are some data, and we’re going to come out with a DNN-based solution in the future” without actually saying it.
I don’t think Phonak is going to give outdated information in marketing literature like this. Nor do I think that Oticon is lying about the noise reduction they can achieve under some circumstances, though it surely is presented in the best possible light.
Are you saying that the improvement is 12 dB from Neural Noise Suppression plus possible additional improvement from directionality? If so, does Oticon mention anywhere the combined number which would be even more impressive? If not, why not?
I’m not a representative of Oticon so I cannot answer your question on how Oticon chooses to publish their SNR numbers, and why this or why not that. I only read their whitepapers and look at their Genie 2 software to interpret the most information I can get out of it.
If Oticon informercial claims an additional 2 dB improvement on the Intent over the Real, and the data in Genie 2 supports that by showing 12 dB for the Intent as a Neural Noise Suppression performance parameter over 10 dB max for the More and Real, then that’s what presented and you can take their info at face value and choose to believe it or not.
Other than that, it’s really useless to nitpick over how much of that is from directionality and how much is really from the DNN, and whether Oticon mention anywhere a combined result to make their results even more impressive or not. I personally don’t see Oticon mention anywhere any kind of combined result. As to why or why not, it’s probably better if you ask Oticon support because I’m not Oticon support.
As far as I’m concerned, it’s pretty obvious that Oticon claims up to 12 dB of Neural Noise Suppression for the Intent 2, which is squarely a DNN feature in their illustration, so I just take it at face value. But of course you don’t have to. But I see no need for me to nitpick whether their 12 dB claim is misleading like you think, because maybe some of that is from directional and only part of that is from DNN, simply to justify that Phonak is not wrong in their claim that no hearing aid brand has been able to implement a DNN solution that can yield up to 12 dB yet.
I’m just stating 2 conflicting things that I see out of the Phonak paper:
Phonak claims that no hearing aid brand has been able to deliver a DNN that can yield 12 dB noise attenuation to the market yet on an April 2024 whitepaper they released.
Yet Oticon claims that their next generation DNN 2.0 in the Intent can deliver 12 dB noise attenuation already. And they’ve already delivered a DNN 1.0 solution as early as 2021 with the release of the More, then Real, despite Phonak’s claim that there’s no DNN-based solution for hearing aid yet to reach the market to date.
It’s really up to the readers here to digest this information as they see fit.
As I said earlier, I struggle to understand some of this stuff. But my take away was that Phonak says that no hearing aid chip currently has the capacity to handle DNN processing in the real world, while Oticon says that they use DNN in the laboratory to create the algorithms used in their Sirius chip. If I am playing in the right ballpark there is no conflict between the two papers on this issue. (I almost let autocorrect get me on the laboratory/lavatory mix up )
I have no earthly idea how it is working in the Oticon Real1 aids but it sure is helping me understand speech so much better. No, it hasn’t given me back normal hearing, no hearing aid can ever do that. But it has made my life much better. And I will be so happy to see if the INTENT1 aids can help me even more, even if it is just a small improvement.
I am always the optimist. It is what has gotten me this far in my 76 years. It isn’t always possible, but being negative is becoming depressed and that isn’t an option.
It’s really irrelevant to use semantics like you did above to justify that there’s no real conflict with what both companies are saying, because what’s relevant is not about semantics to justify no conflict, but it is about the ability to get the job done.
Oticon is smart enough to recognize that the training of the DNN is the most compute resource intensive part of the whole implementation, so they moved it out and upstream into the labs where it can be done with all the compute resources in the world, then they only put the condensed smart that can easily fit into silicon into the hearing aid’s chip. And they did this 3 years ago.
Phonak, on the other hand, if what you’re interpreting above is correct, is still maintaining to this day that “DNN processing in the real world MUST BE DONE ON the chip” and therefore cannot be done yet by anybody in the HA industry.
How am I using semantics? As I understand it, Phonak is saying they are not yet able to use DNN inside the hearing aid in real time while Oticon is saying they use large computer powered DNN software in the laboratory to create rules that are used inside the hearing aid in real time.
 )
)