Oticon doesn’t do it in the traditional way. The traditional way recognizes a noisy environment (like the AutoSense feature on Phonak for example) and can automatically adjust the directionality of the mics on the hearing aid to beam form to the front and attenuate sounds very aggressively on the back and the sides.
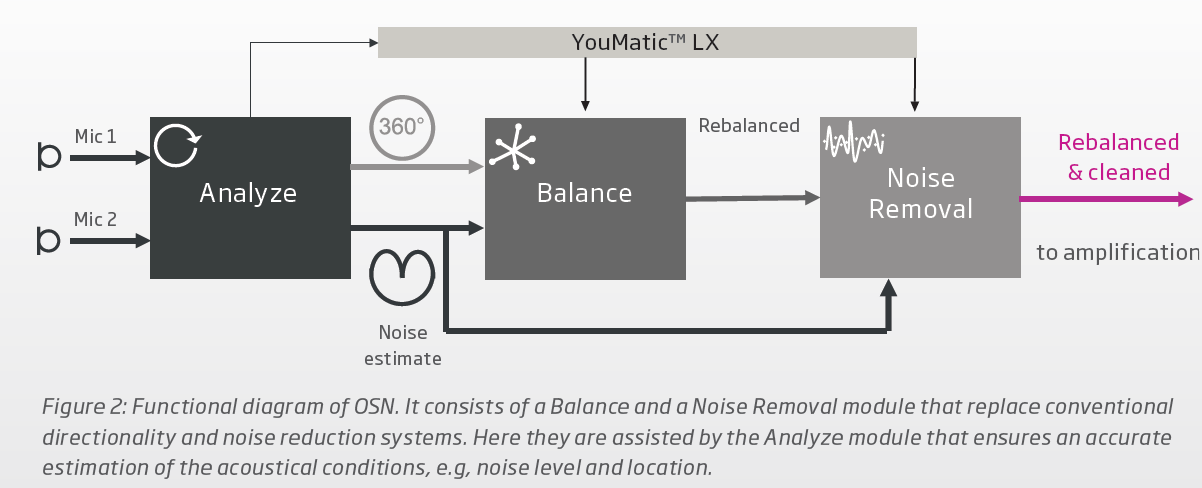
Oticon does do noise reduction via beam forming, but differently. Oticon uses a technique called MVDR (minimum variance distortion-less response) beam forming. Oticon uses the omnidirectional mic to pick up all 360 degrees surrounding sounds, and the back facing cardioid beam to create a noise estimator (see screenshot 1 below, and figure 2 of the screenshot 2). But if there’s speech on the side and the back, then that speech becomes an exception and is preserved via a Voice Activity Detector and not considered a noise source. Then Oticon uses the MVDR beam forming to “balance” the sound scene to attenuate the noise sources on the sides and the back (as part of the noise estimator), yet preserve the speeches that may be found in the back (like that speech between the 2 car noise sources in Figure 3 below).
So the difference is that with the traditional beam forming, the mic pattern adjustment simply blocks EVERYTHING on the sides and the back and only focuses on the front. With the Oticon beam forming, its type of beam forming only attenuates the noise sources found in the back and the sides, but makes exception for speech detected in the back or the sides.
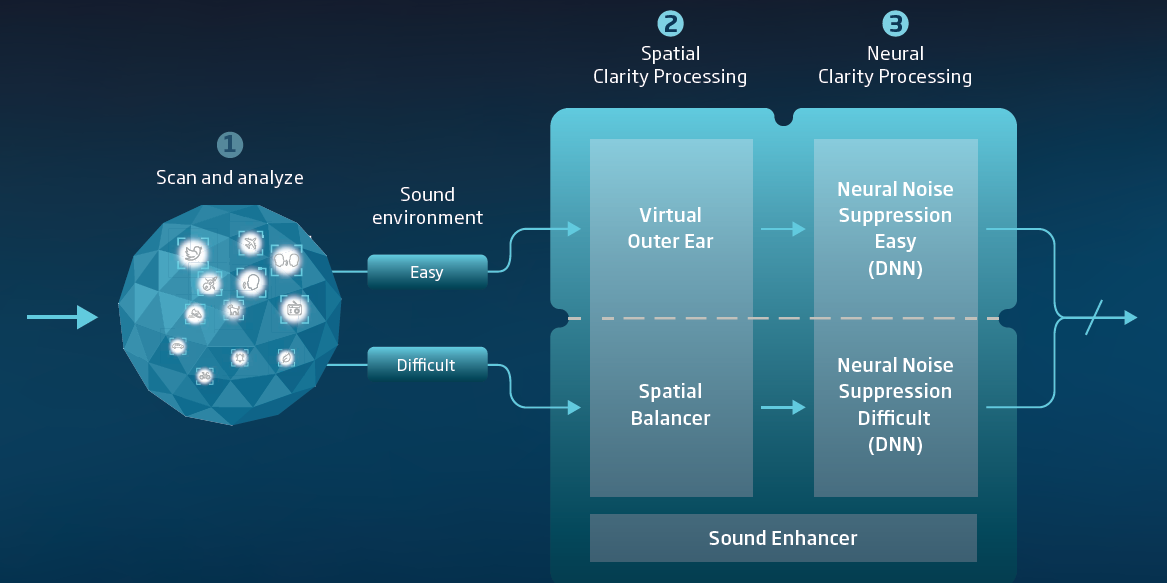
This balancing is the core technology in the original OPN, got carried over to the OPN S, and also exists in the More and Real as the renamed Spatial Balancer (see screenshot 3 below), which is only employed for Difficult environment before it’s fed into the DNN. In the More and the Real, the DNN becomes the core technology, but the Spatial Balancer remains a very important part of the noise reduction scheme as well.
This special and different beam forming technique using MVDR allows noise attenuation but not as aggressively as the traditional way, so you can still hear the noise in the back and the sides, albeit rebalanced as to not overwhelmed speech, so that the 360 degree open paradigm is preserved. Meanwhile, the beam forming in the traditional approach very aggressively blocks out all sources on the sides and the back, regardless of whether there’s speech on the sides and the back or not. So it’s almost as if you have the blinders on to the front sounds only.