I don’t think the open paradigm is about training your brain to need less SNR. It’s just about providing SNR in a different way. Noise reduction is still applied to speech in the OPN for better SNR, it’s just done in a different way, dynamically as opposed to statically. The dynamic noise reduction employed by the OPN is applied momentarily to speech when it’s present, but when speech is not present, it lets the other “noise” come in. The static noise reduction is the traditional way of many hearing aids to block out the “noise” all the times, even when there’s no presence of speech.
I’m guessing that the Oticon More expands on this principle, but with DNN, it is not limited to being able to apply dynamic noise reduction on speech in the front only, but now it can apply to speech in any direction because it can now dynamically come up with a dynamic noise model instead of relying on a location-based (sides and back) noise model like it does on the OPN.
If it can determine through DNN more accurately which sound is which like it claims, it can probably discreetly decide which sound is more desirable to bring forth and which sound to fade out in a sound scene, therefore achieving a better balance. But the sound scene is evaluated dynamically, so the adjustment to the sound scene is constantly instantaneous, giving you the impression consistent of the “open” paradigm.
All this is just a guess from me based on what Oticon is saying. But the bottom line is that I really doubt that it is trying to train the brain to reduce reliance on SNR. It’s probably just applying SNR a lot more smartly and dynamically so that it happens so quick you don’t even notice it.
I’m most interested to find out if this works well for reverse slope hearing loss. I’ve not been happy with any hearing aids that I’ve tried over the past 10 years and that’s even after trying professional programming and tweaking with self-programming (although self-programming had improved results for me).
OPNs were the next on my list since I’ve tried Phonak (twice) and Resound.
I think for reverse slope hearing loss, the secret is in how the HA manufacturers build this kind of hearing loss treatment into their fitting rationales. Conventional wisdom seems to imply that amplification be focused on the lows where the loss is for a reverse slope loss. But Oticon has published some papers showing that their studies find it more effective to treat reverse slope loss for speech clarity by actually focusing on amplifying the mids to highs instead, and they’ve built this reverse slope loss strategy into their VAC+ fitting rationale that way.
Since I doubt that the Oticon VAC+ fitting rationale would change between the OPN S and the More, you can probably try out the OPN S and not wait for the More to see if it helps. But since the More is right around the corner (hopefully), you might as well wait for the More to benefit from the DNN stuff as well.
Regarding ASHA and OPN S…it’s actually implemented now but in the Polaris platform…not OPN S. If someone from the Oticon PR team have mentioned ASHA implementation then this guy definitely didn’t lie…unless OPN S is explicitly mentioned in this context.
Very interested to know if the Costco Phillips will have this technology! 9/4 I received my Healinks and if this becomes available soon at Costco would be worth it to return and have the newest technology!!
I’m going from vague memory from soon after ASHA was announced. Resound already had it and I believe both Starkey and Oticon stated they were planning on implementing. I don’t remember specifics, but since OPN S was relatively new, it was easy to infer that it might get the upgrade.
They didn’t say that the new Phillips lineup will have the Deep Neural Network technology, but they said it’ll have the “AI Sound” technology. I wonder if it’s really the same thing or not. Deep Neural Network is basically Deep Learning, which is generally a subset of AI anyway.
If you have 6 months to return at Costco, I wouldn’t rush out to return right away, but instead wait near the 6 months to see how things pan out further first before I’d decide.
If anyone from Oticon is reading this board, I would be interested in the side-to-side width of this More device in mm. Just so Oticon understands, the dimension I am looking for is 10mm in the rechargeable OPN S1, and 9mm in the version with replaceable 312 batteries. I’m looking for the width of the new rechargeable version. (ergonomic issue here).
Well maybe I’m missing something here but I don’t see or read much into the Oticon More hearing aid.
Made for iPhone and compatible with modern Android devices*, you can stream music, phone calls and more directly to your hearing aids from your smartphone. So with this new aid did Oticon get rid of the Oticon Connect Clip? Or is that still needed for various streaming connections?
Take control of your hearing aids on your smartphone via the app, Oticon ON Connect with your Hearing Care Professional remotely via your phone for convenient online hearing aftercare (hearing aid adjustments etc.) with Oticon RemoteCare. - Well all great except the fact that most Audiologist can’t do AI adjustments from their offices, because most Audi’s have not upgraded (costly) their equipment. I’m not sure AI is going to take off since (one) its still somewhat unproven, (two) I’m sure a good majority of audiologists are not going to pay the cost to offer such service and (three) sometimes you just get better service sitting in front of Audi to discuss hearing aid issues.
No battery changes. With rechargeable batteries you can plug in your hearing aid in the evening and be fully charged for the next day after you have had a good night’s sleep. Boy - how does Oticon think this is “ground breaking”? Last I checked rechargeable batteries have been around for seven plus years.
With Oticon’s handy accessories you can stream sound directly from your TV and other Bluetooth compatible devices. Guess this answers my first question. The connect clip still lives - unfortunately.
So really all the Oticon More comes down to is “On-board Deep Neural Network” which give access to all the “Sound you hear Naturally”. Well I thought all hearing aids give access to sounds, be they natural or unnatural.
Oh well - be looking forward to future reviews but have to ask “where is the beef”?
I have nice results with marvel/paradise and REM fitted to NAL-NL1. Like, I got best possible speech comprehension immediately.
I have loss similar to yours, forum is just behaving stupid about my graphs so it’s not currently there.
Btw, I’m happy to see you here. When i started researching my loss type, your blog post was the first most informative I’ve seen on that topic, then later on I’ve found this forum.
Of course, if I’m not mistaken you for somebody else, but I have a feeling I’m not
@Volusiano thanks for clearing things up about oticon and how their open paradigm works.
What I’ve gathered so far didn’t ever specify that they do do noise cancelling when speech is present.
Musician’s are better in noise than non-musicians. Anecdotally in my experience, pilots tend to have fantastic speech in noise processing–much better than what you would expect from their audiogram. So unless we presume that people are self-selecting for professions based on their auditory skills (they could be), there is a strong suggestion that practicing listening makes you better at it. As for specific training, there are a lot of claims and not a lot of good studies. I’m not convinced that doing something like LACE will necessarily be better than learning the guitar, or creating your own listening practice paradigm (have a loved one read you a book, slowly add in background noise). Hearing aids can be thought to contribute to “training” by restoring audibility and activating auditory pathways that would otherwise atrophy, but there’s no reason to think that Oticon’s hearing aids would do this better than any other.
As for Oticon’s philosophy of trying to provide the brain with the natural cues that it needs, I generally think this is a very strong guiding principle for them (that is, I approve of it). There are two sides to this:
On the one hand, hearing aids themselves may interfere with the natural cues that the brain uses to process sound, and any strategy they can employ to eliminate the problems they themselves cause can be thought of a supporting the brain’s natural processing. For example, the Resound ONE tries to restore pinna filtering with its in-ear mic, the Unitron Tempus tried to emulate it with frequency-specific directionality, Oticon has been maintaining a floating linear speech window for a long time to try to maintain speech spetral cues, Unitron (and others) use ear-to-ear communication to try to maintain appropriate inter-aural level differences. All of these approaches are trying to provide the brain with the sound that it expects.
On the other hand, the ear with hearing loss is damaged. Dynamic range is reduced, but also frequency and temporal discrimination are reduced leading to a general smearing of time and pitch cues. This leads to a loss of localization, a loss of SNR. Hearing aids cannot correct that, so they have to work around it and improve SNR in other ways. Directional mics are an effective intervention. Oticon found a different way to try to comb out background noise while limiting beam forming. The Phonak Paradise has a quiet new feature that I believe multiplies the waveform in soft environments to emphasize speech cues. All of these strategies also bring in a certain amount of distortion as well, which has to be balanced with their benefit.
As for exactly what Oticon is introducing, I certainly cannot tell from this press release. I’m sure it will be good, because they are always good, but less impressive than their marketting because their marketting is always hyperbolic. “Deep neural network”, hmm?
I spend $6k on my current OPNs and they work better than my last Oticon aids or the 2 different Resounds before that.
As a musician, I can still hear pitches well, I can distinguish between what all the instruments are doing at the same time to make up the whole, and I can reject noise well.
When it comes to speech, all bets are off. I can’t listen to one person and tune out the others in a crowded room. My impression is that I can’t focus on the direction the person I want to speak with is coming from and reject the others. I have trouble with consonants too, even with the aids.
If the new Oticon technology can solve that problem, without diminishing the music for me, it will be worth the money.
I play music for a living, and have always used musicians ear filters but I got a misdiagnosed allergic reaction to dust mites 3 times. They got the cause the 4th time but by then I had quite a bit in the land of S’s and T’s, B’s and Ds and so forth.
I think the RemoteCare thing is already available on the OPN S and is not a new thing for the More. And this has nothing to do with AI (Artificial Intelligence) adjustments, it’s just remote adjustment of the parameters on the hearing aids to avoid the office visit.
I don’t fully know the mechanics of the RemoteCare feature, but I suspect that it doesn’t require the HCP to invest or upgrade to costly equipment to enable this. Most likely they talk on the phone with you to see what you want to adjust, then make the adjustment on Genie 2 like they normally do, then just upload the data online somewhere on the Oticon servers and this data is downloaded onto the ON app on your phone which is then downloaded to your hearing aids wirelessly. That’s just a guess, but it’s not like doing REM that would require investment in hardwares specific for it. It’s most likely all software-based.
I don’t think Oticon is claiming the rechargeable batteries to be ground breaking. The only ground breaking thing they’re talking about is the Deep Neural Network stuff.
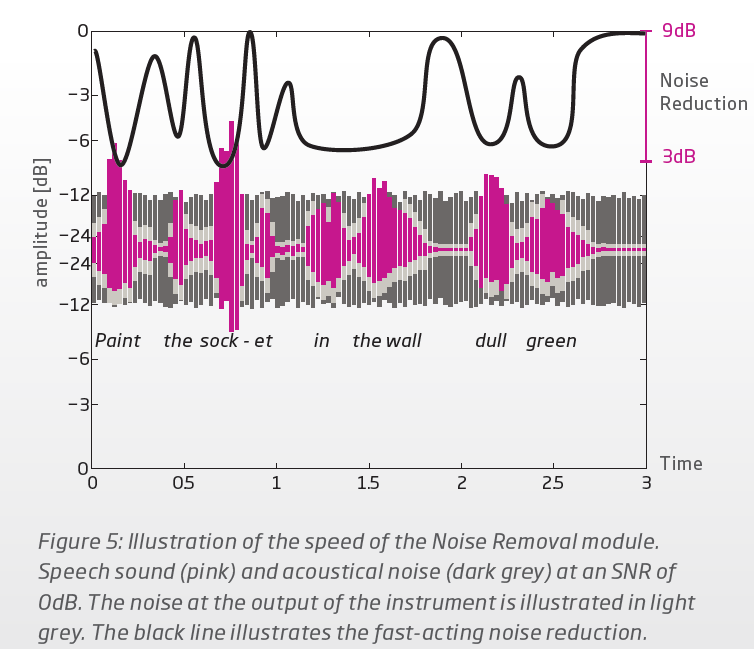
No problem. Just to illustrate, below is a snippet from their whitepaper showing an example of how the dynamic fast acting noise reduction occurs during a speech line for their OPN and OPN S hearing aids.
My comments were related to “cut and paste” off rasmus_braun’s first post. I was just pointing out that Oticon seems to be pumping the fact that the Oticon More uses rechargeable batteries. Why that’s necessary is beyond me. Remote Care could be the future but I’ve seen a few audiologists over the last few years and all have told me - they don’t have the capability to do such adjustments. No big but I think the whole concept of making distant wireless HA adjustment will take a while to get started.
So we await reviews (thumbs up or down) on the Deep Neural Network stuff - as you say. I wonder if Oticon is going to offer “On Board Deep Neural Network” upgrade on all future hearing aids/sizes or just limit the Oticon More to say a canal aid that uses 312 rechargeable battery?
I think it depends on whether they can fit the new Polaris platform chip into an ITE size HA or not.
I think the full shell ITE OPN was big enough to fit the Velox platform chip into it, but the half shell and smaller ITE HAs have some reduction on functionality. If we extrapolate from this, maybe they’ll be able to offer full Polaris functionality into the full shell ITE version of the More, whenever they get to that point.
I don’t hear they mention an offering for a disposable battery version of the More mini-RITE. I’m wondering maybe the Polaris platform with DNN has a significant enough current draw that a disposable battery version of the More miniRITE is no longer a viable option. The future seems to be heading toward litihium-ion rechargeable anyway, given the extra draw from streaming content and now the DNN and what-have-you.
Speaking of which, maybe if the current draw is real enough of an issue that requires a rechargeable version, if there’s going to be an ITE version of the More, maybe they’ll have to make it rechargeable as well.
If any Federal employees or retirees with Blue Cross are interested in the Oticon More (or plan to buy any new HAs soon), please read this: I have BCBS Federal Basic. Up until now BCBS Basic has provided a HA benefit once every three years. Starting in 2021 that will change to a HA benefit once every FIVE years.
I called BCBS and was surprised to hear that the way it works is if you buy HAs in 2020 and use your benefit, you will be able to buy new HAs and get the benefit again in 2023 (apparently the 3-year limit is grandfathered in for the next 3-year cycle). But if you complete your HA purchase any time in 2021 the five-year period kicks in and you won’t be able to get the benefit again until 2026. Big difference.
I have been waiting for Oticon to release something new to replace my current Opn1 HAs. Hopefully I can arrange to buy the More HAs by December 31. I might even buy them without trialing them if I have to.