I think the 4D sensor approach to figure out the user listening intent is mainly about varying the output SNR between speech and noise (balancing the constrast between them) with respect to the complexity of the the listening environment. Below is a chart that Oticon uses to illustrate it. If you make it out to be a very big deal (like the typical Oticon marketing seems to hype things up), sure, you can poke a lot of holes into it via different scenarios.
But if you just see it for what it really is, just a rough and simple way to “guess” your intention so that it can help make speech clearer for you or not, then if the automatic adjustments (based on the 4D sensors) match with your intent, then great. But even if it doesn’t really match your intent, really not much harm is done. You may not get the “best and most optimal” result, but you can still get decent results regardless. At least, if anything, you can still get better SNR (contrast between speech and noise) compared to the Real without the 4D sensor feature.
That much is evident in the chart below. If you look at the black dashed line, that’s the kind of SNR speech vs noise contrast you can get between complex environments (high SNR) and simpler environments (low SNR). If you switch to the Intent and don’t even enable the 4D sensor yet, you can still already get an average of about a 1dB improvement in SNR speech vs noise contrast, most likely thanks to the new and improved DNN 2.0 which does the retraining using 256 channels instead of the 24 channels in the original DNN 1.0. This is seen by the blue dashed line on the chart. So again, even without 4D, you already get better SNR speech noise contrast with the Intent.
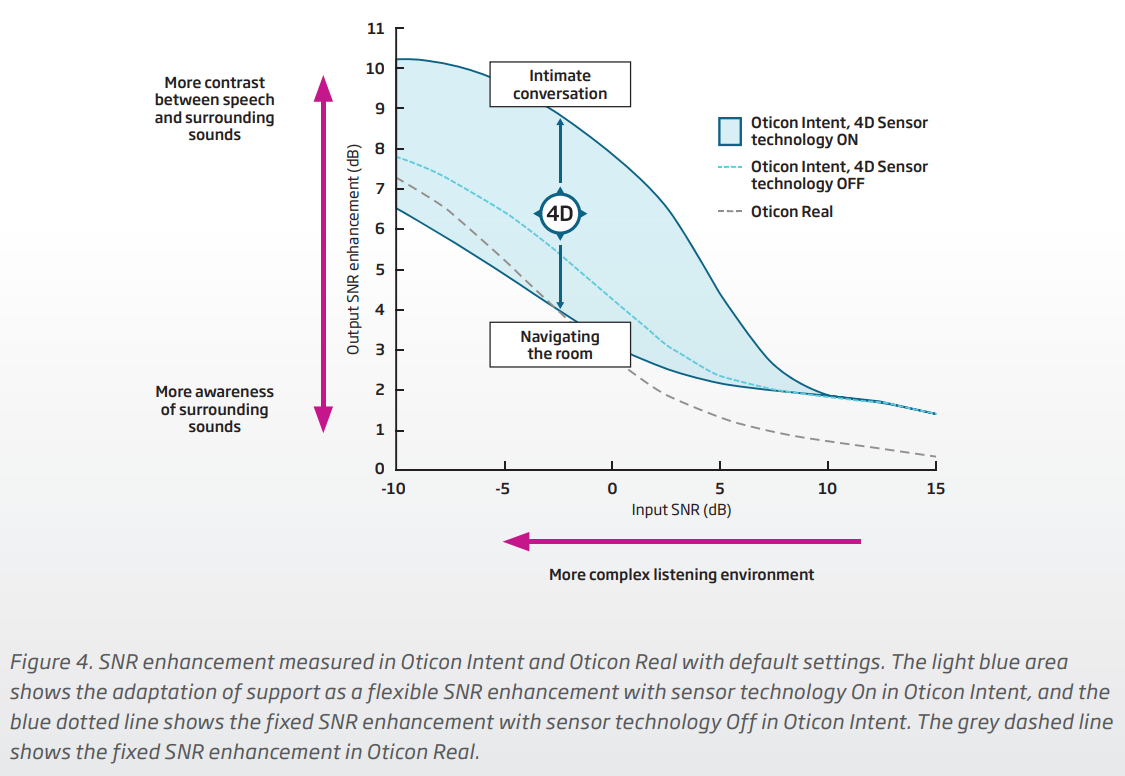
Now if you turn on the 4D sensor feature, you can see that the SNR contrast starts opening up even more. Now instead of a single blue dash line of SNR contrast, you can get even a lot better contrast, and this varies with the guessed intent, spreading out into a “spectrum” as a function of the intent. The bottom line is that the SNR contrast is rarely worse than what you get with the Real (except in the very noisy place, if the guessed intent is wrong), but it can get a heck of a lot better (even better than if the 4D sensor is turned off) if the guessed intent is correct.
Then main take away here is that even if the guessed intent is wrong, there’s really little harm or foul because the worst case scenario is that you’re only down about 1 dB of SNR contrast, but still generally 1 dB better than the Real for the most part. But the upside if the guessed intent is correct (as long as the 4D sensor feature is turned on) can be as much as 2 dB SNR contrast better than if the 4D sensor is turned off.
My take away from this is that the DNN 2.0 is such a big step up from the DNN 1.0 in terms of being able to get more improved larger SNR contrast that sometimes, too much of a good thing is not necessarily desirable, because too high of a contrast of speech over noise may snuff out the noise too much as to cause a huge imbalance. If max SNR contrast is always used, then it would not be consistent with the open paradigm.
Therefore, Oticon has to figure out a mechanism that has more input parameters to determine what a good balance between speech and noise is. The speech detector (1 of the 4D sensors) plus the acoustical environment (another one of the other 4D sensors that determines the complexity of the environment) are the 2 sensors that have already been used in the past in the OPN and the More. With a tighter SNR contrast range before in the OPN and More, these 2 existing sensors were enough to help select what the SNR contrast should be. But now that the SNR contrast range has been much better improved, Oticon needs to come up with more input parameters to determine what the appropriate SNR contrast value should be within that wide of a range of possible SNR contrast values.
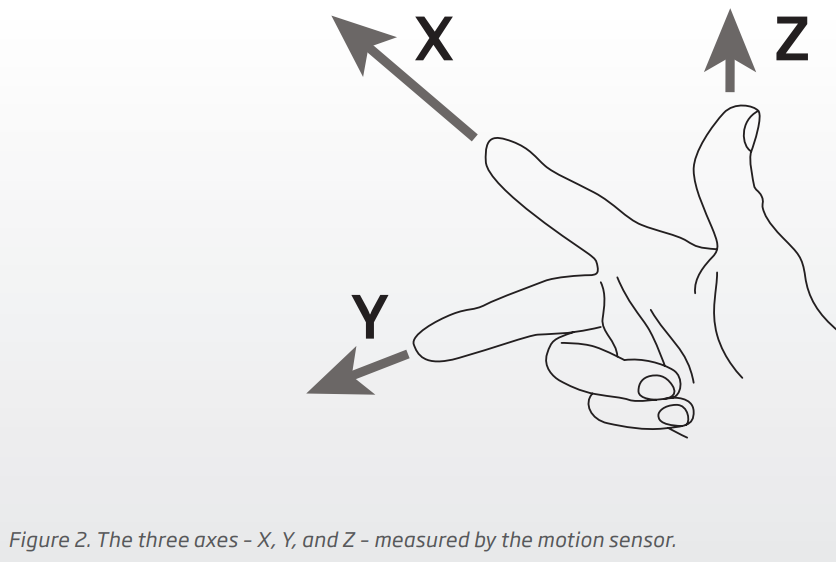
So by using the accelerometer to measure the XYZ axis, with the Z (vertical) axis being the head bobbing up and down, they can emulate the body motion of the head bobbing up and down when walking, and the X and Y axis being the turning or leaning forward of the head, as the 2 additional inputs for the remaining 2 sensors (body motion and head motion). This helps guide them to figure out where inside that wider range of possible SNR contrast (that they can now afford thanks to DNN 2.0) to determine and assign the most appropriate SNR contrast value to and be consistent with the open paradigm.
Remember, the bottom line is that even if the XYZ head and body movement doesn’t really match the user’s real intent, it’s still better than nothing. It’s still better than the Real, and it’s still (hopefully) more accurate than being conservative and just assign a dash blue line of SNR contrast instead of using the guessed intent to open up this possible band of SNR contrast as widely as possible.
The take away is that the 4D sensor for the intent can’t be worse if the guessed intent is wrong anyway. It can only be as good or better than with no guessed intent. So why not have it? There’s really nothing to lose and a lot to gain.
One additional comment I’d like to make (as if I haven’t made enough already, lol) is that the way Oticon changes parameters when moving from simple to complex environments, and anything in between is very, very smooth. It’s not like with other brand using something like an autosense to “jump” from one program to another. Oticon changes their listening parameters seamlessly inside of just the one program that is whatever the user is selecting. So I don’t really think that the user would notice stark contrasts of program changes as they move their head around or they bob their head walking around. It would only be the sound scene balance (the sound balancing between speech and other sounds) that may change as the head is moving or bobbing around. So the experience hopefully should be quite seamless, if past seamless performance of the OPN and More and Real is of any indication. And besides, the guessed intent is focused on finding that balance between speech and other sounds, with speech being the primary sound component in focus here. So if the guessed intent is wrong and you move your head to strain more to hear speech better, it can usually be get better or the same and not worse, or else you would not have moved and strained your head to hear speech better in the first place. Just my opinion here. Only anecdotal experience we hear from future Intent users will tell.