If they are just using the motion sensor, I hope they are doing something more with them than the companies that have already been using the motion sensor.
3 Likes
Agreed, one can only imagine how it works when driving or another activity with a lot of turning, but where you don’t necessarily need constant re adjustment of the directional pattern.
1 Like
I think the 4D sensor approach to figure out the user listening intent is mainly about varying the output SNR between speech and noise (balancing the constrast between them) with respect to the complexity of the the listening environment. Below is a chart that Oticon uses to illustrate it. If you make it out to be a very big deal (like the typical Oticon marketing seems to hype things up), sure, you can poke a lot of holes into it via different scenarios.
But if you just see it for what it really is, just a rough and simple way to “guess” your intention so that it can help make speech clearer for you or not, then if the automatic adjustments (based on the 4D sensors) match with your intent, then great. But even if it doesn’t really match your intent, really not much harm is done. You may not get the “best and most optimal” result, but you can still get decent results regardless. At least, if anything, you can still get better SNR (contrast between speech and noise) compared to the Real without the 4D sensor feature.
That much is evident in the chart below. If you look at the black dashed line, that’s the kind of SNR speech vs noise contrast you can get between complex environments (high SNR) and simpler environments (low SNR). If you switch to the Intent and don’t even enable the 4D sensor yet, you can still already get an average of about a 1dB improvement in SNR speech vs noise contrast, most likely thanks to the new and improved DNN 2.0 which does the retraining using 256 channels instead of the 24 channels in the original DNN 1.0. This is seen by the blue dashed line on the chart. So again, even without 4D, you already get better SNR speech noise contrast with the Intent.
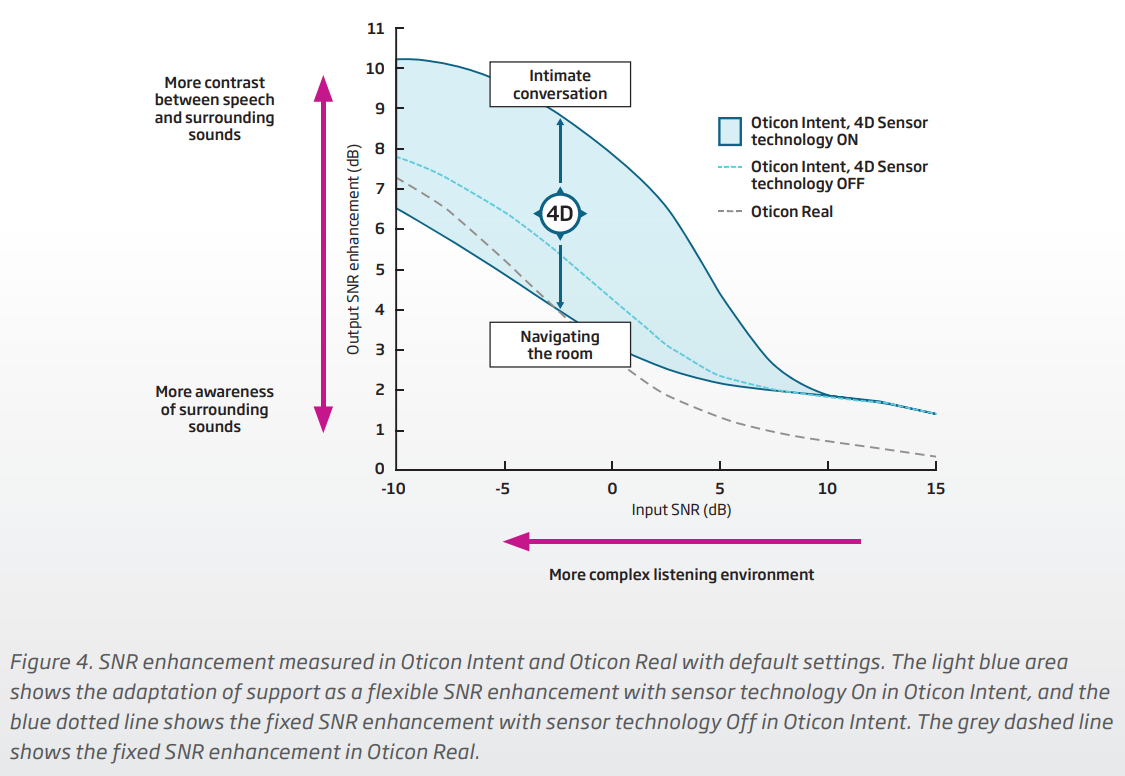
Now if you turn on the 4D sensor feature, you can see that the SNR contrast starts opening up even more. Now instead of a single blue dash line of SNR contrast, you can get even a lot better contrast, and this varies with the guessed intent, spreading out into a “spectrum” as a function of the intent. The bottom line is that the SNR contrast is rarely worse than what you get with the Real (except in the very noisy place, if the guessed intent is wrong), but it can get a heck of a lot better (even better than if the 4D sensor is turned off) if the guessed intent is correct.
Then main take away here is that even if the guessed intent is wrong, there’s really little harm or foul because the worst case scenario is that you’re only down about 1 dB of SNR contrast, but still generally 1 dB better than the Real for the most part. But the upside if the guessed intent is correct (as long as the 4D sensor feature is turned on) can be as much as 2 dB SNR contrast better than if the 4D sensor is turned off.
My take away from this is that the DNN 2.0 is such a big step up from the DNN 1.0 in terms of being able to get more improved larger SNR contrast that sometimes, too much of a good thing is not necessarily desirable, because too high of a contrast of speech over noise may snuff out the noise too much as to cause a huge imbalance. If max SNR contrast is always used, then it would not be consistent with the open paradigm.
Therefore, Oticon has to figure out a mechanism that has more input parameters to determine what a good balance between speech and noise is. The speech detector (1 of the 4D sensors) plus the acoustical environment (another one of the other 4D sensors that determines the complexity of the environment) are the 2 sensors that have already been used in the past in the OPN and the More. With a tighter SNR contrast range before in the OPN and More, these 2 existing sensors were enough to help select what the SNR contrast should be. But now that the SNR contrast range has been much better improved, Oticon needs to come up with more input parameters to determine what the appropriate SNR contrast value should be within that wide of a range of possible SNR contrast values.
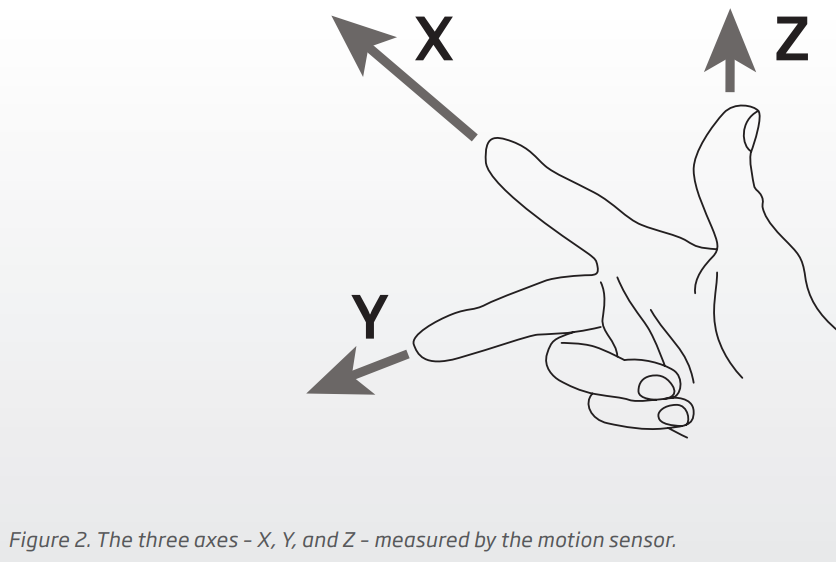
So by using the accelerometer to measure the XYZ axis, with the Z (vertical) axis being the head bobbing up and down, they can emulate the body motion of the head bobbing up and down when walking, and the X and Y axis being the turning or leaning forward of the head, as the 2 additional inputs for the remaining 2 sensors (body motion and head motion). This helps guide them to figure out where inside that wider range of possible SNR contrast (that they can now afford thanks to DNN 2.0) to determine and assign the most appropriate SNR contrast value to and be consistent with the open paradigm.
Remember, the bottom line is that even if the XYZ head and body movement doesn’t really match the user’s real intent, it’s still better than nothing. It’s still better than the Real, and it’s still (hopefully) more accurate than being conservative and just assign a dash blue line of SNR contrast instead of using the guessed intent to open up this possible band of SNR contrast as widely as possible.
The take away is that the 4D sensor for the intent can’t be worse if the guessed intent is wrong anyway. It can only be as good or better than with no guessed intent. So why not have it? There’s really nothing to lose and a lot to gain.
One additional comment I’d like to make (as if I haven’t made enough already, lol) is that the way Oticon changes parameters when moving from simple to complex environments, and anything in between is very, very smooth. It’s not like with other brand using something like an autosense to “jump” from one program to another. Oticon changes their listening parameters seamlessly inside of just the one program that is whatever the user is selecting. So I don’t really think that the user would notice stark contrasts of program changes as they move their head around or they bob their head walking around. It would only be the sound scene balance (the sound balancing between speech and other sounds) that may change as the head is moving or bobbing around. So the experience hopefully should be quite seamless, if past seamless performance of the OPN and More and Real is of any indication. And besides, the guessed intent is focused on finding that balance between speech and other sounds, with speech being the primary sound component in focus here. So if the guessed intent is wrong and you move your head to strain more to hear speech better, it can usually be get better or the same and not worse, or else you would not have moved and strained your head to hear speech better in the first place. Just my opinion here. Only anecdotal experience we hear from future Intent users will tell.
4 Likes
I apologize for my immediate cynical response. It’s a good thing if HA manufacturers attempt new ways to improve the capabilities of devices. Of course the marketers will take things as far as they can. Look, today’[s hearing aids are remarkable!! I’m glad that so much research and development has gone into them. Best wishes to Oticon and this new approach. i mean that!
1 Like
While I am always intrigued by the developments being made in the hearing aid world, I am a little skeptical in regards to the deep neural network and the supervised learning it does based on “trained situations.”
I’ll have to wait and see reviews if and when they do come out to weigh the real world pros and cons as opposed to lab generated results to prop up the product. I’m cautious, but optimistic in this regard.
I wonder how many “scenes” (or inputs or whatever) Oticon’s new 2.0 DNN was trained on compared to the 1.0 version. I saw a bubble chart awhile ago illustrating how many inputs the GPT4 AI program was trained on vs. GPT3 and how many more inputs GPT5 will have been trained on when it is released. The differences in the number of inputs is HUGE! And the increase in the capabilities of each version of the program was dramatic.
I imagine that a HA DNN would be a lot different from an AI program, but, especially if the number of training inputs is much larger, this new DNN 2.0 might turn out to be a significant improvement.
As always, I will wait for some real-world reviews on the Intent before I make a decision to consider an upgrade from my Oticon Mores. The ability for me to read reviews on new HAs is one of the most important benefits of this forum to me.
Geez, with the names of these HA models it’s almost difficult to avoid making puns!
2 Likes
What’s interesting to me about this step for Oticon is that they’re focusing on the same issues that Signia did when they introduced the IX platform with RTCE (Real Time Conversation Enhancement) last September. Signia also uses motion and acoustic sensors as well as soundscape analysis. In the introduction to this white paper, the authors were responding to issues which were first investigated in academic research.
Given all of this, I see the Oticon Intent as part of a larger trend and that we will see all major hearing aid companies introducing their own versions of new technology to improve the ability of hearing aids to help us achieve better comprehension of speech in noisy environments especially when there are multiple speakers.
I think that “Intent” is a poor choice of words and leaves the whole effort open to criticism. No device can in fact know any brain’s actual intent. I suspect that if the Oticon engineers were asked, they would readily agree that intent is not really what they’re after. The marketing people tried to come up with a single word to capture the essence of these new hearing aids. This choice of words was not a home run - to say the least. More like they swung and missed.
Like Oticon, Signia published a lengthy (14 pages) white paper to explain their new technology. I found it helpful to read the 2 white papers side by side to best understand what they’re trying to accomplish - albeit one of them doing it with a DNN and the other without. Here’s the link to the Signia white paper:
Ahh, thanks for the photo.
Yes, they are doing exactly what Signia and Phonak are already doing, but implemented via their opn/dnn strategy rather than with directional mics.
I want both though. I want oticon’s neato background noise management PLUS beam forming in complex situations.
4 Likes
Actually in the Oticon white paper linked above by Member 42, it says that the Intent IS using some beam forming (directional mics). (Horrors!)
“Intent-based Spatial Balancer uses a minimal-variance distortion less response (MVDR) beamformer to create the optimal balance for the given sound scene by creating bigger contrast between meaningful and less meaningful (often noise) sounds.” page 4, Intent-Based Spatial Balancer
Neville, can you elaborate on how Phonak is addressing this? Thanks in advance.
2 Likes
Ah, interesting. Does the other stuff stay on or turn off when they turn on the beam former. On would be preferred, but I don’t know whether it would be difficult.
Signia and Phonak are opening their dmics and re-assessing the environment when you start “navigating the room” (aka, moving).
3 Likes
MDVR beamforming has already been used by Oticon way back since the OPN and OPN S (they call it part of the Balancer), then it got renamed the Spatial Balancer in the More and the Real. Now they expanded the name out to Intent-Based Spatial Balancer.
Below are 2 screenshots from the Oticon OPN OpenSound Navigator whitepaper that talks about the MVDR beamforming way back then.

The original DNN 1.0 uses 12 million sound scene samples. It’s not clear how many sound scene samples were used in the DNN 2.0, but Oticon said that the sound scene samples used for training the DNN 2.0 were more diverse than those used in DNN 1.0. Oticon also said that complex sound scenes were used to train DNN 2.0 (but they didn’t say if DNN 1.0 sound scene samples were also complex or not). One would have to assume that the DNN 2.0 should have been trained with at least the same amount of sound scene samples if not more. But it’s a mystery why Oticon didn’t want to say exactly how many samples were used for the DNN 2.0. It’s likely, however, that Oticon didn’t start with DNN 2.0 and retrain it with new data from scratch.
It’s also very likely that Oticon just took the already trained DNN 1.0 and improved it with added new training sound scenes that are more complex and diverse on top of the 12 millions original sound scenes that were already trained on the DNN 1.0. This means that the original 12 millions sound scenes are already “baked in” to DNN 2.0. So this would make the question of how many sound scenes were trained in 2.0 compared to 1.0 become irrelevant because the original 12 millions were baked into 2.0 by default already.
In the training analysis that compares the DNN 1.0 output against the real sound scene, 24 channels were used. In the DNN 2.0, they claim to have upped the training analysis to use 256 channels instead of 24 to improve the training accuracy. Because of this, Oticon claims that it helps provide more attenuation than with the previous DNN without distortion to the sound (up to 12 dB attenuation in difficult environments as opposed to only 10 dB before). Oticon also says that the DNN 2.0 is also produces a clearer output while preserving more of the original cues.
Yes, I would call the Oticon AI the DNN type of AI, while the Philips 9030/9040 AI is not advertised as a DNN AI, but more as an AI algorithm, although it does require training samples as well. The Oticon DNN 1.0 requires 12 million sound scene samples, while the Philips AI requires hundreds of thousands of noisy speech samples.
What does this hearing aid will do in practice that’s the question we user have to answer. Theoretically everything is possible.
Signia can face up to 3 people and fokus them, but … you cant select them and that is what I don’t think and what I would say … no … it don’t work. eg. you are walking down the street, in front of you is a girl that is doing a phone call … behind you is a couple that is talking to each oder … so the Signia is fokussing them … and now what happens when your buddy next to you is speaking? 
Resound Nexia or also Oticon Real had the intension to fokus on a specific sound, that could be nice but … Nexia I didn’t like it when in a restaurant suddently the voice of people from the table behind me are jumping in the hearing systems … I didn 't found it usefull when I hear people from the opposide of the train platform are fokussed but not the one next to me …
Intent now seems to be a system that I can fokus on my own … restaurant: I am fokus my buddy in front of me, as long as I keep fokusing him everything arround me will be slightly muted and the buddy fokussed … there is a laughter? oh when I start heading my head looking arround then the hearing aid will stop fokussing on the buddy … i can still hear him but I also can hear the location from the laughter and maybe the discussion of it better … same situation when the other buddy next to him starts to talk … I will move the head toward him and suddently the fokus is on this person …
I hope that I will never have such a situation anymore that a voice from behind is suddently louder then the one I would like to fokus, if this is the case this would be great, because if I want to hear this sound I can move my head and listen
That’s all theoretically, praxis will show if this is a future thing or if this will not work, but this option can also be set off if you cannot handle it.
3 Likes
That’s exactly what they’re doing, and pushing it as some kind of 4D magic or unheard thing. Signia does that too and it’s close to useless. The SoC (system on chip) that they all use has embeded gyro.
Guess it was easier for them to produce market babble out of this rather than implement LE Audio/Auracast.
Disappointing.
Certainly your emotions are also a function of the brain. I perceive the “intent” is more directional. A quick head turn to the right would direct the aid to focus sound reception to the right. Sitting stationary, facing forward while watching TV, would focus reception towards that direction. I could see the benefit of such “intent.”
2 Likes
Yes, theoretically everything is possible. And what these systems do in practice we’ll find out.
With regard to Signia, their white paper explains that they have proximity detectors, so they wouldn’t be giving the same priority to the girl talking on the phone as they would to your buddy next to you. Nor would they be focusing on the couple behind you because they monitor conversations in the front hemisphere.They also use acoustic sensors to develop a picture of the conversational soundscape in terms of who’s talking to whom and who’s esponding to whom. Motion sensors are also used to identify who the wearer is paying attention to, they have attempted to deal with the problems you’re raising with the tools available as best they can.
Does it work? I don’t know. I hope to trial a couple of these and find out for myself.
All SoC are not the same, right? Oticon says:
“Sirius . . . (with) high processing capacity . . . is a . . . platform built just for hearing aids”
Nothing new here?
Well I tried the Signia 7IX and I have to say that in the first fit (and some little changes) they were nothing for me. They were a disaster at the party, I could hear everything, but I didn’t understood nothing, very annoying evening with nearly no support from the hearing aid … but of course for someone else this could be a good solution
So you interpret the graph in the whitepaper as being valid in a scenario where the guessed intent is wrong. Say you’re listening to speech coming from your side, and the 4D subsystem wrongly determines that you really want to hear what’s in front of you. Maximizing the SNR of speech in front of you will adversely affect how you hear speech from the side, won’t it?