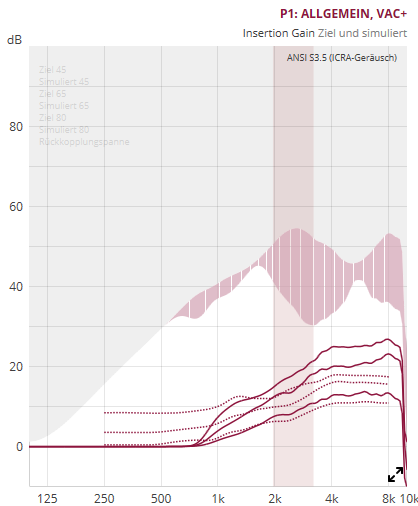
I managed to almost get rid of the hissss, but there are drawbacks.
Perhaps first i should mention, that i use VAC+.
On the one hand, as Oticon is inventor of this formula, their permanent adjusting noise control works best with it. At the other hand, their strategy is to enable understanding of speech without unnecessarily distorting the auditory impression that the wearer is used to without the aids (as long as i hear about the same number of birds in my garden as other people, i do not care wheter they would sound more brilliant if i had more compensation). So VAC+ does sound a lot softer than NAL, the speech understanding ist not compromised (or there is enough room to enhance it further) and it’s much more comfortable to start the aids in the morning (and to forget to put them out in the evening  ).
).
So with VAC+ i have the smallest possible gain and more room to add anhancements.
If i compute VAC+ and i’m happy with what I get, the noise level is acceptable. But as soon as i enhance the low sounds with the basic controls for sound perception (“more detail”), the noise gets untolerable.
First, i determined, where the noise (mostly) is.
This is tedious, but by using a type of binary seek, i found that (corrected by my audiogram) the noise is almost completely in the range 2-3KHz. Note, that it does not make much sense to try single bands (there is a lot of information outside the curves!)
Then i tried to decrease the lo-compression (meaning, that the 45db-insert is close to the 65db-line) in this range.
On the other hand i found, that it almost makes no difference to enhance the range above 4KHz.
So i got something like
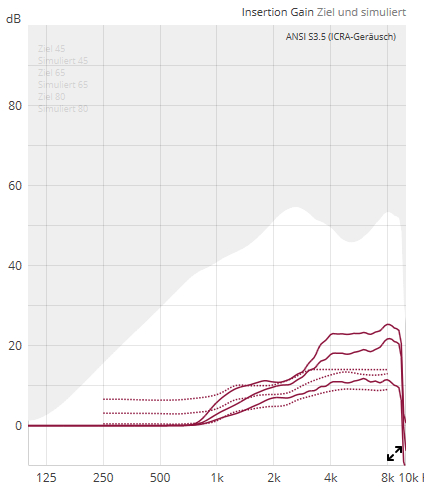
(i first enhanced the lo and mid-level at the complete range by 2db 'cause this improves my speech understanding dramitically ).
Now the noise was almost gone!
But there is no free lunch:
When you look at the speech-banana, you will find that 2-3KHz is nearly unnecessary to understand speech. But it is essential to recognizing music. This is something different to having a dedicated program for music listening.
If you lack 2-3KHz and you are in a quiet area with low background music, you will understand people talking and perceive everything to get oriented in space - footsteps, doors, glasses etc. But the music will be cut down to a chaotic sound that is quite unpleasant; eventually the DNR does an additional task to “assist” you. Although it’s very low, you cant’t ignore it, but you do not know what is played there. And it is really surprising, when you get near the speaker and hear now - hey, this unstructured noise is Michael Jackson, that i heard a hundred times before.
So this program is really valuable in some situations, but it is not suited for general use.
I constructed an additional program without the nonlinearity, but a low dedicated perceivable noise by adding a huge 4-10KHz boost to an unmodified VAC+basic:
At the moment this is my favourate.
I’m stopping this post now; it will get too long. But there are some additional thoughts about audiograms and directionality. As soon as i find the time, i will post them.