Artificial Intelligence (AI) is revolutionizing the design and functionality of hearing aids. Here’s how AI can contribute to the development of effective hearing aids:
These features are made possible by AI’s ability to perform tasks that require human intelligence, such as recognizing patterns and making decisions. Over time, AI-powered devices learn from data and adapt their behavior without the need for reprogramming. This leads to a more personalized and improved hearing experience for users1.
AI makes decisions based on the values of the developers. If my values differ from the those of the developers of the AI system I’m using, the results will not be optimal for me.
HAs, like just about everything else, are compromises. I have a very hard time believing that AI can tell me what compromises will best satisfy me. Or you, or anybody else.
@Don
The dispensing audi didn’t set them up right.
I’m grateful he got the hearing aids for me. I was almost run over several times at work because I couldn’t hear fast noisy diesel loaders behind me. The new hearing aids solved that problem. The setup created others. I couldn’t hear in noise. I couldn’t hear in quiet.
When we parted company at his request we shook hands. Turns out he had reset my hearing aids and done a quick fit erasing all the programs in the Paradise P90R’s. I had to reset volume to the max to hear at all. Forget about hearing in noise!
I found a hearing aid practitioner who did a quick fit using the same hearing test. I could hear so much better. I asked him what he found wrong…the L hearing aid wasn’t set up to communicate with the R hearing aid, which should have been the master of the two. And the dome setting was wrong. 6 months later I had a new hearing study done. My hearing was 5-10 dB worse. And he boosted mids and high frequencies.
I’ve been back two more times for hearing tests to confirm. My hearing was worse again.
My questions: why haven’t I had REM?
My observation: it takes me quite a while to adapt to changes with my hearing. I need to be patient.
My setup didn’t work. The audi tried to fix it for about a year and a half before we parted at his request. I had said that I think there is something simple that we’ve missed.
Frankly I’m more impressed with the AI response than I thought I would be. These are the third set of Phonaks I’ve had due to exposure to loud noise at work for years.
Finally, key is to find a good audiologist or hearing instrument specialist and do business with them. I learned I must advocate for myself better.
@DaveL → thanks for starting this thread. It’s a great topic to share and discuss.
One kind of AI adaptation that I don’t see listed on your Bingo list is the use of AI training (not real-time learning) to execute certain tasks to alter the sounds. Usually this type of AI training can be real time or can be pre-trained, if real time learning capture is not feasible in the setup. Most of these are in the form of a deep neural network model. A very highly public type of this kind of AI DNN is the Tesla Full Self Driving software available on Tesla camera-equipped EV cars. It takes videos of Tesla car driving and feed them into their FSD neural network to train the network on how to drive like humans, because the actual driving videos are those performed by actual human drivers.
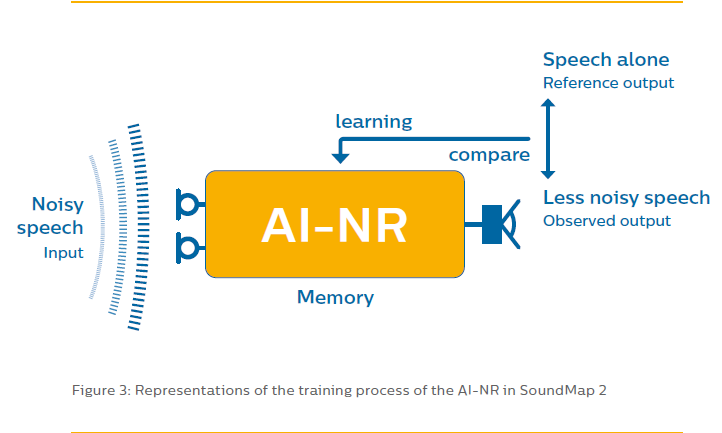
Anyway, back to AI self-training system, the Philips 90x0 hearing aids uses AI to do noise reduction to improve speech clarity. It feeds hundreds of thousands of noisy speech samples into an AI system that is designed to clean up the noise from the speech. Then it compares that cleaned output against the reference clean speech sample to see how well the system did. If the system didn’t do a good job, it feeds the discrepancy between the less noisy speech output and the reference clean speech output back into the system to adjust mathematical parameters inside the system to arrive at the minimal (least) possible discrepancy for that outcome. Then another noisy speech sample gets fed into the AI system again, and the cycle repeats for hundreds of thousands of noisy speech samples until the AI system is trained well enough to produce acceptably clean output for the most part in real life. Below is an illustration of that AI Noise Reduction system implemented in the Philips 90x0 sold at Costco.
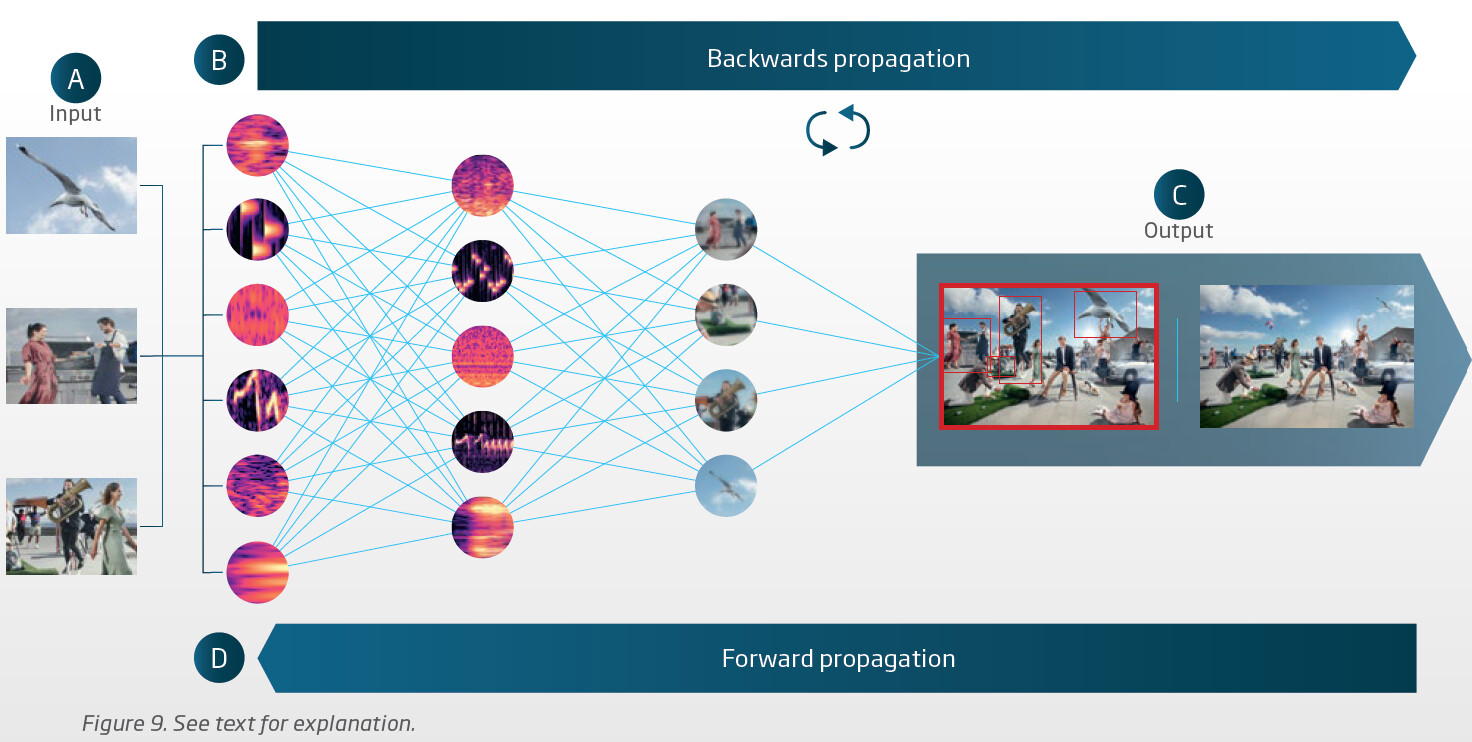
Along the same vein, Oticon also uses AI in the form of a deep neural network (DNN) and it captured 4 million sound scenes and fed it into their DNN designed to break up the sound components of the sound scene and rebuild it again. After forward propagation of the sound scene in the DNN, the resulting output (a recreated sound scene) is compared against the reference (original sound scene) for discrepancies. The discrepancies are fed back into the system (backward propagation) and mathematical parameters associated with the neuron models inside the system are adjusted in order to come up with a minimized discrepancy on the output. After training this DNN with 4 million sound scenes, Oticon deemed it sufficiently good enough to release into their Oticon More lineup, followed by the Oticon Real. With the Oticon Intent lineup that came after the Real, Oticon improved their DNN to a version DNN 2.0 which takes in more sound scene samples that are more versatile to make the improvement.
Below is a conceptual view of the Oticon DNN. The whole point of capturing the sound scene and rebuilding it is that in the process, the sound components in the sound scene are broken up/individualized, then recreated and put back together into the whole sound scene again. This breakdown and rebuild approach affords Oticon the ability to have controls in the process of rebuilding the sound scene, like how to rebalance the volumes of the sound components based on the user’s input in the programming software, to make the speech sound components louder, and other non-speech sound components not as loud, but still noticeable enough as to not be missed. And perhaps more droning sound components like mechanical noises can be subdued more aggressively. This approach also preserves the integrity of the Oticon promoted “open” paradigm, where sounds are not blocked out due to directional beam forming in order to let users hear all sounds and not just sounds in the front.
Below is an Oticon YouTube video that gives an overview of the Oticon DNN
Below are just some pretty good YouTube video links explaining how DNN works, in case there are some technical geeks in here like me who would like to know more about DNN. Otherwise just ignore the links.
My dispensing Audi did some good things. Until the end I spoke highly of him in his office. I regularly told him I couldn’t hear. We made minor improvements. A year and a half later I kept saying I think it’s something small.
On bad days I would tell myself for the price they should set themselves up. I never said that to him.
In August almost a year and a half ago we stepped into a huge maize. We never got out.
I see your posts and Neville’s and other caring audiologists. I am so grateful you’re all here. Picking an Audi myself feels like entering the maize with the dispensing Audi. Trouble is finding my way out of the maize with hearing aids that work
How should I tell my dispensing Audi I can’t hear the way my HA’s are set up?
AI:
It’s essential to communicate openly with your dispensing audiologist about any issues you’re experiencing with your hearing aids. Here are some steps you can take to address this:
Be Honest and Specific: When you meet with your audiologist, express your concerns candidly. Let them know that you’re having difficulty hearing even with the hearing aids. Be specific about the situations where you struggle (e.g., noisy environments, conversations, etc.).
Describe Your Challenges: Share details about the specific challenges you face. For instance:
Do you hear ringing or buzzing sounds (tinnitus)?
Do you experience balance issues?
Is it hard to follow conversations, especially when there’s background noise or multiple people talking?
Ask for Adjustments: Your hearing aids might need adjustments. Request that your audiologist fine-tune the settings based on your feedback. They can modify volume levels, adjust frequency response, or address any other issues.
Trial Period: Most hearing aids come with a trial period. If you’re still not satisfied after wearing them for a while, discuss this with your audiologist. They can explore alternative solutions or make further adjustments.
Remember, your audiologist is there to help you achieve the best possible hearing experience. Open communication ensures that they can tailor their recommendations to your specific needs.
By continuing your interaction with Copilot, you are accepting the Terms of use and
But I think someone needs to talk and think differently about our future hearing aids.
I feel caught in hearing aid heck
I leave mine in auto. But I can’t hear. So I have to find a program that works. Then when I want to go back to auto it can take a while. Or I pull out my loser of a cell phone start the app. That takes minutes
And my Audi wouldn’t use the app for setup. He wouldn’t get paid by workman’s comp.
If you’re referring to the “AI” processor, it does not have to be in the final implementation of the hardware. The compute resource requirements and restraints/limitation only have to exist and be dealt with in the training phase, not in the implementation phase. Beside the compute resource requirements, there is also the data (acquisition) requirement and the time requirement it takes to collect and train the DNN. And all 3 of these things (compute resource, data collection, and training time) are setup in the labs behind the scene and then executed, but the final implementation is a condensed version that only needs to possess the “how”, and not the “what needs to be done to get there.”
Let’s take a tennis analogy, perhaps Roger Federer’s brain. He started playing tennis at the age of 8. At that point, the neural network in his brain AS FAR AS TENNIS IS CONCERNED is almost a blank clean slate. But as he started learning to play tennis, the neural network in his brain receives training data from his practices and matches, and corrects and improves itself over a long period of time before he becomes a master at tennis. So the real investment is that vast amount of data his brain collected over a very long amount of time to acquire and train his brain, eventually until he’s good enough. But his brain is not any bigger (ignoring the human physical growth between the age of 8 until adulthood), it’s just wired differently between the neurons so that it knows how to control his motors to play tennis better.
What this analogy is missing is the vast computing resources like the computing machines that need to exist in order to do the training, but don’t need to exist in the real human brain. The sensorial inputs to collect data (like the eyes and ears and feel) are similar to the videos and photos and sounds for the AI computer system, but the real human “processing” in the real human biological brain is already there and readily built-into the brain very efficiently. Meanwhile, the non-biological artificial “processing” on the computer (hence artificial intelligence) is not already put in place by nature like the biological brain, so the scientists have to create an artificial computing machine to put in place this artificial processing in the labs.
While this artificial machine is very compute intensive and physically extensive in order to make the processing for the training happen, the end results are simply reduced into finely honed information in terms of mathematically computed values for the parameters associated with each neuron and how the neurons are connected together in the DNN design for the final execution. Basically the final result is the “smart” that was produced through the intensive training, and this condensed “smartness” doesn’t require much silicon real estate to be implemented into a miniature size small enough to fit into a hearing aid.
An analogy is perhaps Einstein’s famous E = MC2 equation. He might have had to go through countless mathematical theories and hypothesis and deductions and calculations and what-have-you’s to arrive at that equation. But in the end, it’s condensed into a very simple formula E = MC2 that says A LOT and perhaps everything about how matters and energy relate to each other.
Another very good example is perhaps the Tesla Full Self Driving capability. Tesla has a MASSIVE amount of computing resources as well as data collection behind the scene to train its FSD neural network on how to drive by itself. But in the end, the final implementation of its FSD is actually in the software itself, and can simply be broadcasted and updated over the air into the car’s (much simpler) computer, and the condensed smart built into the latest FSD software version can just drive the car by itself better and better with each and every newer version.
Thanks for making this point. As a chess player, I see the analogy with how AI improved chess engines (one of the earliest triumphs of AI): by “learning” chess from playing thousands and thousands of games on a heavy mainframe system you end up with a program that beats any GM, even if nobody knows exactly how its algorithms work (a radical change from how earlier chess programs worked). But those “engines” then can be implemented on relatively simple devices like your smartphone. Thus, AI may require heavy GPUs to learn how individual users extract useful information from noise, but then implementing its findings will hopefully require far fewer resources.
It is my understanding that AI-based solutions don’t reduce the resources required in the implementation phase. For example, AI-based search is much more resource-intensive than regular search, to the point where the extra computing power needed is a problem for the huge corporations providing this service.
Getting back to hearing aids, the size of neural net data stored in aids will have a linear relationship to the size of the training neural net. And the digital signal processing that’s applied in real time to the live sound scene is of similar complexity to the processing applied to sound samples in the training phase.
I believe that as we have seen with Oticon aids that the tinny step from the More to the Real has taken more power to operate the aids. And the step from the Real to the INTENT aids is requiring even more power. My reading on the Oticon users page of Facebook that mostly ladies are complaining about the size of the INTENT aids, the extra width. And I expect that the creation of ITE or completely in the canal aids will be not even possible, even with removal of connectivity. But the advent of LE audio does seem to be a plus for less power usage. But I forsee myself streaming more once I get the INTENT1 aids. I really enjoy listening to audiobooks. And maybe I can enjoy listening to music again.
It really depends on the AI-based solution. Your understanding is only on a very narrow view of only certain AI based solutions. It doesn’t apply to ALL AI-based solutions. But the AI training approach I described above that doesn’t require the same extensive resources to execute does apply specifically for the DNN setup of hearing aids like the Oticon aids and the Philips aids. The same for Tesla Full Self Driving AI.
If ALL AI-based solutions don’t reduce the resources required in the implementation phase like you argue here, then how do you explain that hearing aids are able to use much more reduced resources that can be condensed on a chip that can fit into a hearing aid? That’s a fact that has already happened for real. And how do you explain Tesla being able to just send FSD software updates to their simple car computers and keep on improving their self driving capability? That’s another fact that’s already happened for real as we speak.
It’s pretty obvious that the Tesla FSD neural network model is actually implemented via software, as an OTA software update is all is needed to give the car a new version. It’s not clear whether the Oticon and Philips DNNs are software based or hardware based, as we’ve never seen any firmware update announcement for the More or Real that has any mention of an improved DNN. But regardless of whether it’s a software based DNN model, or a hardware based DNN model, any of these implementation phase versions use reduced resource that either fits onto a small enough silicon chip for a hearing aid, or even fits on a software-based version, compared to the resources required for the training phase.
If it were a real time on-the-fly self-training AI setup, then OK, it probably uses the same resource that does both self-training and execution. But the Oticon and Philips DNN are not real-time self trained DNNs in the firtst place. And that’s probably also why they’re not designed as real-time on-the-fly self training AI systems, just for the reason that a more intensive compute resource setup is not required to begin with.
The field of AI application is vast, and there are many different ways to skin a cat. Your understanding of it as you argue here is only a very small subset of the many possible AI approaches.
OK, getting back to hearing aids, yes, the size of the neural network stored in the aids is the same size of the training neural network. There’s no difference there. But it’s not the size of the neural network that requires the huge computing resources. The huge computing resources required in the training is due to the training process that is applied to the neural network, all the millions of comparisons between the network’s outputs versus the reference data to measure the discrepancies between them, and the back propagation of the discrepancies back into the neural network and the mathematical computation in altering the neural nodes’ parameters in order to determine the appropriate set of parameters that will result in the smallest possible discrepancies for that set of training data in order to get the best outcome.
You should really watch the series of YouTube videos on neural network that I provided the links for in a previous post above in this thread to get a better idea of how the training of the neural network is carried out. Not until then will you be able to get a good appreciation of the effort involved in training it.
Just like a real human brain that doesn’t grow in size between an untrained brain and a trained brain, the actual neural network in the labs and the neural network as implemented into the hearing aids are the same like you said. But, the finally trained skilled neural network is not where the resource hog is. The resource hog is in the years of practicing the skill on the human biological brain, and training time it takes to gradually improve the biological network to the point where it’s proficient enough at what it’s trained to do.
I think you totally missed a whole paragraph in my previous post where I explained that the processing part of a real biological human brain to train it is already built into the brain and is already very efficient by nature’s biological design. But the processing part of an ARTIFICIAL intelligence system to train it does not have the benefit of this nature’s biological design. So it has to rely on the artificial design afforded by computers and machines to simulate the training process and enable training to happen. It’s this behind the scene artificial processing that is computer and resource intensive.
Because newer hearing aid chips, while still less capable than mobile or server chips, still have the resources needed to implement neural network-based sound processing.
Maybe you think that once all the work of training is done, the implementation using the trained DNN has practically nothing left to do. But in order for the hearing aid to do a lookup in the trained DNN, it has to analyze incoming sound to extract the same features that were extracted from the training samples. My guess is that the work required for this analysis dwarfs the work involved in querying the trained DNN. But the AI implementation includes the analysis, not just the DNN query.
What you’re describing above, which you make it sound like a “big” thing → analyzing the incoming sound (to feed into the DNN), is actually NOTHING difficult or resource intensive like at the level of training the DNN is.
The analysis of incoming sound is a fundamental building block of the sound processing done by digital hearing aids, which ALL digital hearings aids can readily do already, WAY BEFORE any kind of DNN implementation was ever invented and applied to hearing aids. The analysis of the incoming sound does NOT dwarf anything, including the querying of the trained DNN.
For example, the Oticon OPN already has a very sophisticated Scan and Analyze functionality that scans and analyzes the environment 500 times a second before feeding its result into other functional blocks for further sound processing. And there is not any kind of DNN involved in the Oticon OPN.
And who is arguing that the implementation of the DNN, or the analysis of the incoming sound that feeds into the DNN, is resource intensive? Not me. Only you, apparently.
The whole point, which you consistently missed, is that it is the TRAINING of the DNN that is resource intensive, not the implementation and execution of the (already trained) DNN.
The oxymoron in your argument, where you said that (all) “AI-based solutions don’t reduce the resources required in the implementation phase”, lies in the fact that you still haven’t been able to answer @cvkemp 's original question, which is “if AI-based solutions require intensive compute resources, then how can they make it small enough at the same time?” It’s actually a very good question to begin with.
Or is it your answer above → “Because newer hearing aid chips … still have the resources needed to implement NN-based sound processing?” If it is, then OK, whatever you say → training AI DNN is resource intensive, but implementing AI DNN is also resource intense, but no worry, the tiny chip in the small hearing aid can still handle it all.
I think size is a constraint. I think battery capacity is a bigger one for me.
When I was a photographer I always asked myself, “Have I forgotten anything that will shut me down?”
Film. Batteries. Flash. Cables. Etc. yes that was way back. I’ve used and run out of film. I had a pro flash burn up. Address-where am I supposed to be?