I have most of my hearing aid issues resolved except for one. I cannot get the full prescription gain in my left ear with closed sleeves, but I am not willing to use molds, so I am prepared to accept the reduced gain to avoid feedback solution.
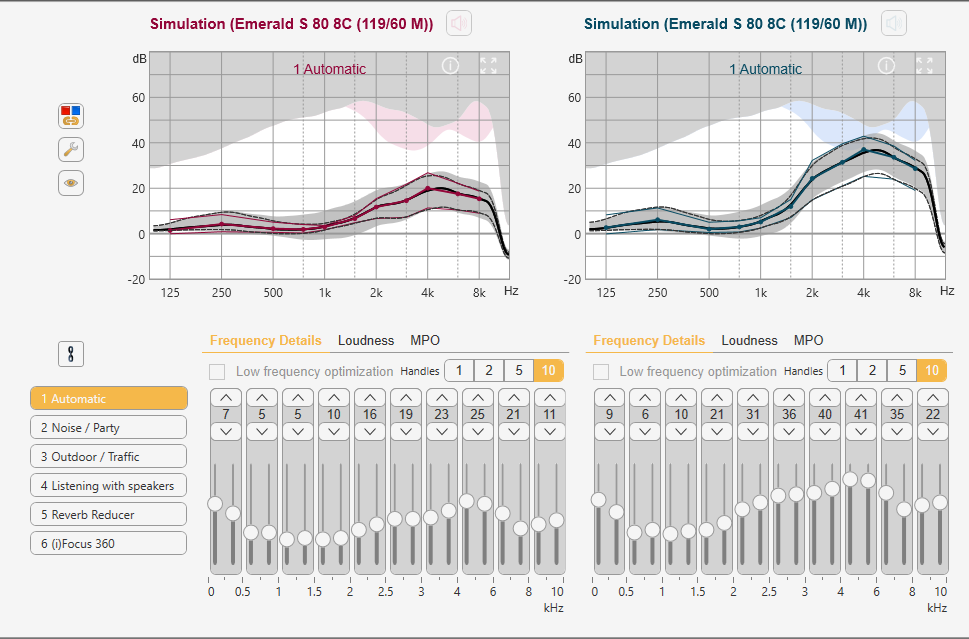
However, my one outstanding problem is that sounds at a distance are unusually loud, loud to the point of interfering with sounds closer to me. I am currently using the Rexton SmartFit prescription formula and it seems to have quite a bit of compression. This is what the gain curves look like in theory. However, I know in my left ear that the actual curves are about 10 dB down to avoid feedback. But, I assume all three soft, normal, and loud curves are down, and the compression range remains.
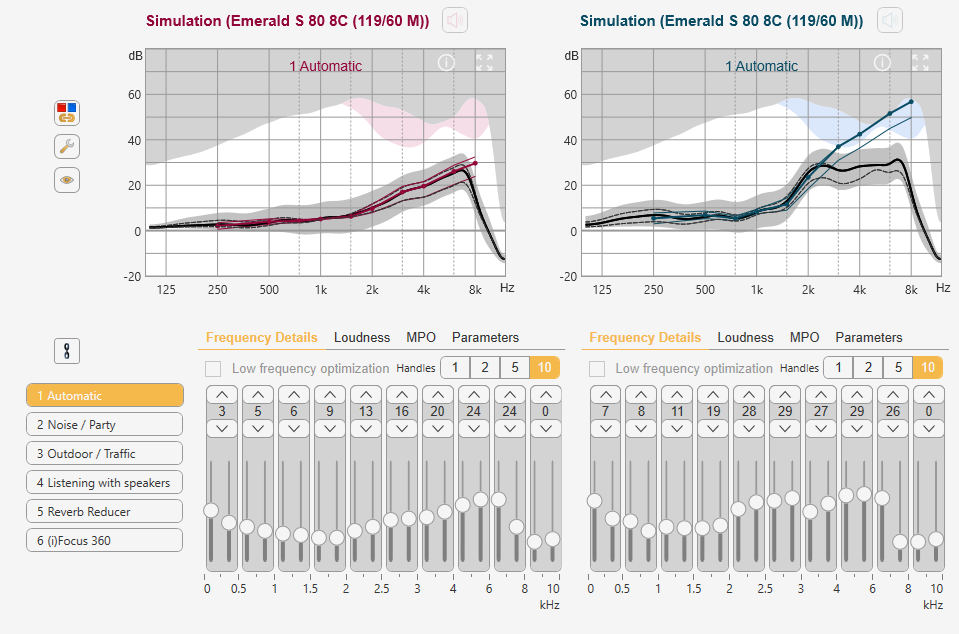
In playing around with the prescription options available, I see that DSL v5 has significantly less compression. It kind of looks like this. However in this case I played around with the gains for the left ear only and reduced gains to keep about 10 dB away from the feedback zone. I am presuming the black curves are the hearing aid, and the blue colored curves are what the formula says. It would take me deep into feedback trouble if they were followed.
What do you think? Am I on the right track in considering DSL v5? I don’t “Do it Yourself” adjust my aids. I just use the software to explore what I could ask my fitter to do. I have researched it a little and found this article below to be interesting. It basically describes what I have been hearing and does suggest compression needs to be reduced.
As I’ve said elsewhere, I’m a heavy DSL fitter (in part for just this reason), so I’m biased.
What are your compression ratios? You could go to DSL, or you could just drop your compression around 3-4 kHz, which is probably where it’s high (or at least, would be with NL2, I have no idea what rexton smartfit is doing).
Signia feedback manager sucks. Have you already tried a double dome in the left? Mind you, with an asymmetry like that you may not like full gain in the left anyway.
I will have to get back to you on the SmartFit compression ratios. I did a short comparison of REM fitted NL2 and SmartFit in the office and picked SmartFit.
Even with a mold and a small vent I could not achieve full prescribed gain in the left year. I have two issues. The mold fixed the feedback. But at some level of gain the sound in my left ear goes to noise. Restricting gain seems to be the only way to avoid it. Bottom line is that I have given up on achieving full gain in that ear. I have not tried the double domes. At least on the computer simulation it does not provide any more feedback isolation. Actual fit may be different.
And here is the compression data for the DSL v5 prescription, including my leveling off of the high frequency gain in the left ear. Ratios are much lower.
Yes, you are reading that right. So, you could just drop the compression at those frequencies if you didn’t want to make such a drastic change. That may resolve the problems you are having with distant sounds with the trade off that you will have less access to soft consonants at those frequencies. There isn’t a lot of research on what the right amount of compression is right now. DSL and NAL have converged a fair bit on their gain profiles since their first incarnations, but as you can see still differ significantly in compression. There has been a bit of research comparing outcomes between the two prescriptions which pretty much conclude “both are good”. High versus low compression is basically a fight between audibility and clarity. With significant hearing loss you HAVE to compress to get access to all the sound. However, the more you compress the more distorted the signal and at the same time significant hearing loss results in a loss of spectral cues and the individual becomes more dependent on temporal cues, which are negatively impacted by compression. So there may actually be sort of a sweet spot for higher compression–mild loss doesn’t need much compression, moderate can benefit from it, but as hearing loss increases it becomes detrimental again. I would love to see research focussing on exactly what those relationship are, which would in turn help to guide our fittings. In my anecdotal experience, severe-profound users often prefer a more linear sound, as do users with theoretically more distortion in the cochlea (e.g. meniere’s).
Signia is one of those companies that doesn’t allow for different prescriptions in different programs, which makes it harder to just flip back and forth and see what you like or what is better in which situations. However, one could adjust one prescription into another with REM, it just takes a bit more time.
One of the things that I am excited about with Widex’s app is the possibility to datamine these sorts of preferences for users with different sorts of loss profiles. All manufacturers have been using AI for a while now, but the Widex system has the potential to be a lot more powerful than that.
Thank you for the thoughtful comments. I have been thinking about where the best place to start with the objective of reducing compression. The Rexton SmartFit seems to have the most, and that is kind of where I am now.
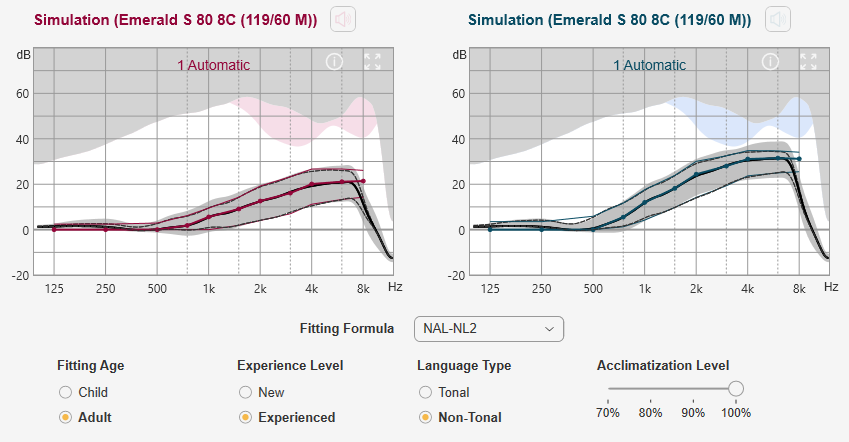
NAL-NL1 has less at least in the higher frequencies. And it seems to roll off the highs to the point where no manual adjustment would be needed. But it still has lots of compression in the lower frequencies, where I am thinking there is still a lot of speech and noise.
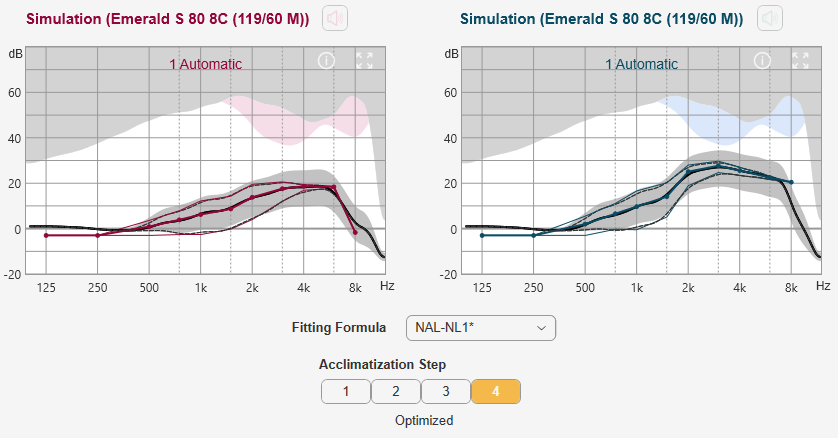
My conclusion considering the alternatives is that the best starting point may be the DSL v5 because it starts with the least compression, and probably does not have to be manually tweaked at all in the right ear. My understanding of these formulas is that they are much more complex than just gain, and compression. They also involve the use of time constants, and knee points for the compression changes. This document about how Connexx implements DSL v5 shows what is involved, and much of it is beyond my understanding of the complexities. My thinking is that these time constants and knee points have been optimized with the gains and compression used in DSL v5, and it would be best not to mess with them. In other words it seems better to start with DSL v5 and change the gain only in high frequencies for my left ear, and leave the rest alone, and trust the overall formula. On the other hand if I was to start with NAL-NL1 and reduce compression I would be mixing formula strategies and could end up with a dog’s breakfast of strategies. Does that make any sense? Also I am thinking it would make for an easier REM process. The fitter is currently using NAL-NL2 and fudging it to replicate the SmartFit gains. With DSL v5 she should be able to measure it and adjust it directly to the target in her Aurical software.
Interesting topic, of which I know nothing as it has been applied to HAs, but I have a question. First, the terms near and far field have meaning in a number of contexts including outside the subject of audio. I am using them here in the simple audio sense where near field refers to sounds heard directly from the source as from on-axis at close range, and far field refers to sounds which include significant reflections of the original sound from other directions (room sound).
To what degree are HAs attempting/able to genuinely discern near vs far field sounds as opposed to essentially guessing based on amplitude?
Sure, echo is really just the slower version, longer delay. But room effect is far less distinctive audibly because the delay is so short. It tends to reduce the apparent directionality and slightly muddy clarity without being heard separately. Higher frequencies are inherently more directional so it’s easier to discern where they are coming from, but they are also inclined to reflect off hard surfaces. A sound which is close may also reflect around the room but the reflections will be extremely soft compared to the original. A sound from a greater distance (particularly indoors) will have reflections that are somewhat closer in amplitude to the original. In both cases the reflections will seem to come from more/different directions and can be filtered out as undesirable echos, but curious about identifying true far field sounds so those originals can be filtered out as well if that’s desired. My guess from general descriptions of features is that there is at least some of that going on but I don’t really know.
Probably not as much as you think. Oticon divides speech into near speech and far speech using modulation rate, but that’s about it. I don’t think hearing aids currently use reverberation beyond just trying to clean it out.
Thanks, you are probably right. The more I think about it the less likely it seems. They are already doing a remarkable amount of monitoring and processing for such a small low power device and probably have a wish list anticipating the next generation of hardware.
They aren’t. They are really only asking for a particular gain at different levels at each frequency, and their compression ratios are just a consequence of that. They don’t speak to time constants–there’s actually not as much talk about time constants as there used to be. Perhaps in part because the industry has settled on what they thing is best for most situations, but also because there new adaptive technologies are doing a lot more stuff with them moment to moment. Some manufacturers still allow you to manipulate them a bit, but many do not.
When I print out the detailed settings of DSL v5 and compare them to NAL-NL2, I see the obvious reduction in compression ratio of the soft sounds from 3-4 down to 1.2. In the louder range CR seems to go down from 2-4 to about 1.7.
The first knee point for softer sounds seems to go up in DSL to about 47 at low frequencies compared to 40 for NL2. And for the second knee point DSL is at 62 compared to 55. However, I have no idea how significant or insignificant that is…
The other obvious difference is that the compression method (CM) used for DSL is Syllabic, while NL2 is Dual. My understanding is that Syllabic uses faster time constants, while Dual is slower. It does not seem definitive whether they are adaptive or fixed. I do see in the software that this can be overridden though. Not sure of the implications of doing that?
I am not familiar enough with the Rexton/Signia hearing aids to be aware of that difference in time constants, but if that is true it is a manufacturer choice rather than a presciption choice. However, when DSL was initially developed I’m not sure adaptive time constants were even a thing–I’d have to check its history (history is not generally my strength, I prefer sci-fi).
I found this PowerPoint presentation by Siemens on Understanding Compression which looks like it dates back to 2006. Here is one slide which seems to suggest they give a choice of Syllabic or Dual Compression and they are both adaptive. But, it is not exactly definitive and they never really define what Dual is. The software does give a choice if you override the defaults. Interestingly it is set on a channel basis, so conceivably you could set it differently across the frequency spectrum.
I thought one of the adjustments that could reduce the problem of hearing distant conversations more loudly than desired was the kneepoint. But I don’t know how one does that.
As I understand it, the knee point is the point on the gain curve where it changes slope, usually to more compression. If the knee point was moved down, it would go to the next gain slope at a lower input sound level.