Widex recently released their new ‘Allure’ model which comes with an enhanced ‘PureSound’ mode. At the same time there is renewed discussion about analog vs. digital.
These things are related. Let me try and explain and also try to cut through some of Widex’s marketing fog. Quick summary:
- Widex’s PureSound mode operates like an analog hearing aid under digital supervision. That’s unique in the industry!
- The big advantage is its super low signal delay, which is particularly beneficial with open fittings
- PureSound also inherits the disadvantages of analog aids: no noise suppression and no feedback suppression
- PureSound on Allure HAs seems to support front focus, vs omnidirectional mode with the previous generation HAs. I wonder if that can be turned on and off.
- Every other Widex mode (even the Music mode) operates like any other digital hearing aid. They might have tweaked things to sound more natural, but there is no magic sauce.
So what’s happening behind the scenes?
Let’s start by looking at sound waves - pretty much everybody has probably seen a representation like this:
This is what sound looks in the ‘time domain’. It shows the amplitude as time passes.
Now there is a fundamental difference how analog hearing aids process sound vs. digital aids. In technical terms:
- Analog hearing aids keep sound in the ‘time domain’. They use analog filters (resistors and capacitors!) to break the signal up into several frequency ranges, and then have a separate analog amplifier for each frequency range.
- Digital aids convert sound to the ‘frequency domain’, do amplification and all kinds of processing there, and then convert back to the ‘time domain’. More details below.
First, here is an overview which features can be implemented in the ‘time domain’ (analog HAs) and which features require ‘frequency domain’ processing (digital HAs):
| Analog HAs | Widex PureSound | Digital HAs | |
|---|---|---|---|
| Adjust Gain per Channel | |||
| Linear Amplification | |||
| Compression | |||
| Beamforming / Directionality | |||
| Feedback Suppression | |||
| Background Noise Suppression | |||
| Wind Noise Suppression | |||
| Environment Classifier | |||
| Frequency Shifting | |||
| AI Processing | |||
| Zero Delay Processing |
Now what’s behind converting the signal to the ‘frequency domain’, which is key to all advanced processing?
It’s done via some amazing math (called ‘Fourier Transform’) and the result is that the original sound wave gets broken up into its individual frequency components. The image below illustrates this:
- On the very left are three individual sine waves with distinct frequencies - think of 3 individual keys pressed on a piano
- The middle shows the combined signal that a listener would hear
- The right shows what happens after conversion to the frequency domain!
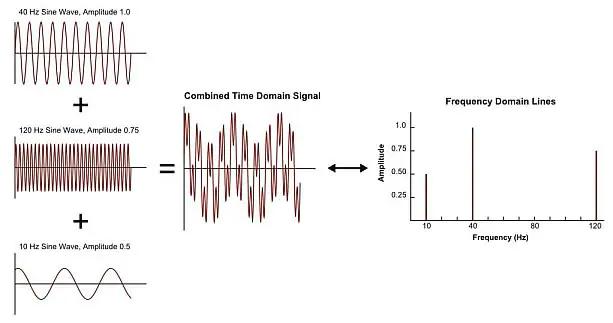
You can see that in the frequency domain, all three individual sine waves are represented by a bar. Not only that, but the louder the original sine wave was, the taller the corresponding bar!
A digital HA can now play with these bars: make them bigger or shrink them according to prescribed gain settings. It can find characteristic patterns that typically represent noise and subtract those. And much more.
When done, the last piece of the puzzle falls into place. There is more math (called ‘Inverse Fourier Transform’) which allows the HAs to convert the signal back from those bars in the ‘frequency domain’ to the time domain.
So what’s the downside?
Delay! Analog processing has zero delay, whereas all that fourier stuff leads to at least 5ms processing delay. Not because today’s hearing aid CPUs are so slow, but because fourier math is not instantaneous but rather needs to look at a certain time period of the incoming sound signal before it yields any conversion results.
Still, it’s immediately clear how this frequency domain stuff is beneficial for hearing aids: It’s super easy to apply the desired amplification to each frequency component when your signal is already in the frequency domain.
Let’s take a closer look at feedback suppression, which apparently Widex PureSound is not very good at.
That’s no surprise, because feedback suppression works by changing the output frequency slightly. If your incoming signal is at 2000Hz and is at risk of causing feedback, then the HA will move the frequency bar (in the frequency domain) slightly to the right so that the signal is now at 2020Hz. Now the output signal no longer has a 2000Hz component, and the feedback loop is disrupted.
Of course changing the frequency is bad for Music, but that’s the price we have to pay for no feedback.
Since you can only shift the frequency when operating in the frequency domain, analog hearing aids (and Widex’s PureSound mode) can’t do that.
So what does Widex do? In PureSound mode they simply lower the gain so that it’s below the feedback threshold. But that means you are likely not getting the amount of amplification you should be getting. Here is what this looks like for my audiogram:
For higher frequencies my target gain (dotted lines) is above the feedback threshold. PureSound simply reduces the gain to below that threshold:

In fairness, that’s why Widex says PureSound is only for mild to moderate hearing loss.
Why did I mention ‘Marketing Fog’ in the title of this thread? Because I get the feeling that Widex is intentionally blurring the lines a bit.
Nothing they say is wrong. But when they talk about how great PureSound is (it is unique and they deserve credit!) and then they talk about improved feedback suppression without mentioning that it only applies to all other modes except PureSound, then that’s, well… That’s marketing fog to me…
… and I’ve seen that in other Widex threads where people lump PureSound and Widex’s Music program together. They are fundamentally different. Only Puresound has no delay.
One last comment:
It’s actually quite amazing that there is a mathematical method to take any signal and break it up into its original sine wave frequency components. Even more amazing that Mr. Fourier laid the groundwork for this math in 1822 already!