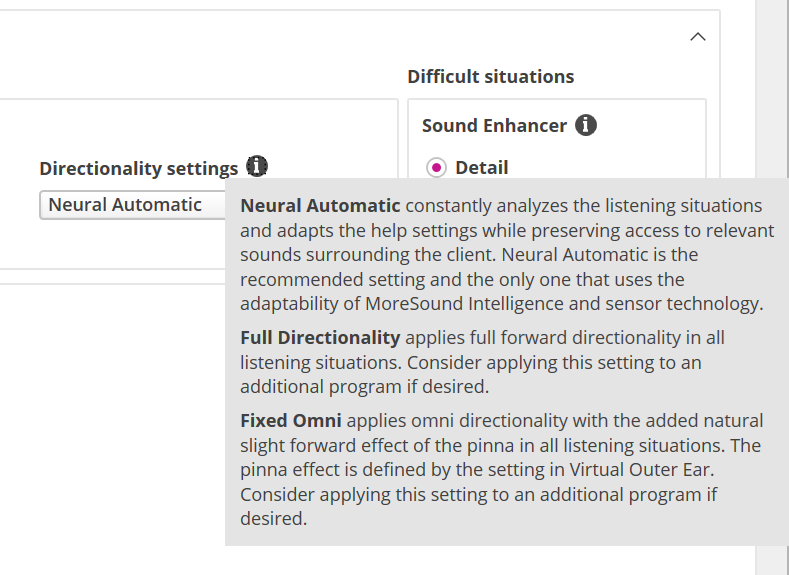
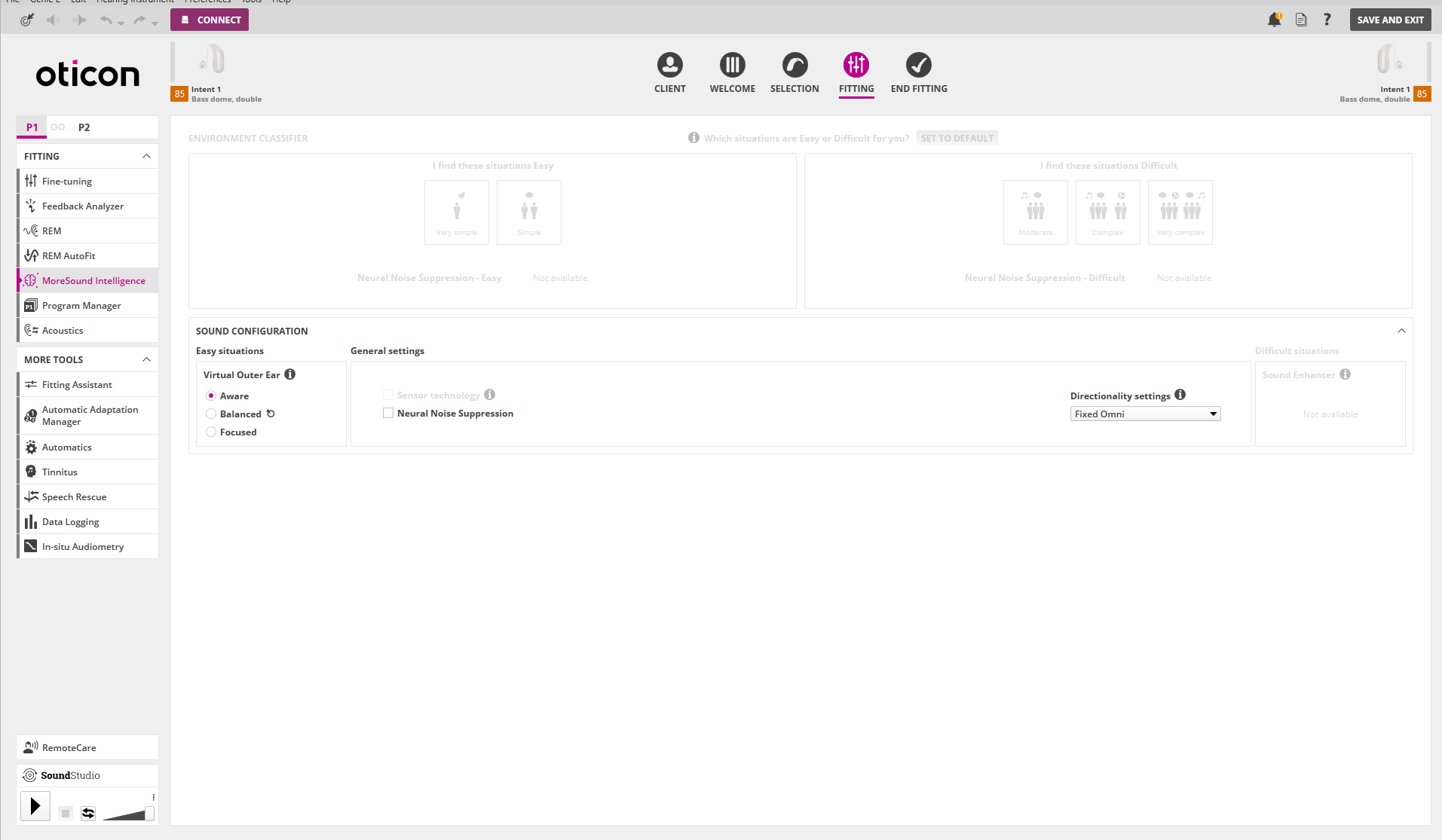
Update: I visited my audiologist and told her that speech clarity is better than the OPN and that the MyMusic program is terrible. She said she had heard other people say the same. We did some tweaks to the General program and the Speech in Noise program but focused on music. She created a new Custom program using VAC+ and copied all the old numbers from the old OPN Music program into the new Custom Music program, as well as turning most functions off. She then created a separate Custom program that was relatively linear, similar to the old amplifiers that some musicians say is the best way to go for music. So I have two new music programs to try.
I immediately tried the two new programs with my violin and my cello. For reference, other people have told me that my cello has a warm, mellow tone and my violin is bright and brash - and this is how they sound to my ears with the old OPNs. With both of the new programs, the harshness of the MyMusic program was gone. The Custom Music program, the one similar to the old OPN Music program, sounded very warm, with both my cello and violin, and the Custom Linear program sounded accurate, almost clinical. I could take either program, but like Goldilocks, I would really like something in the middle. I might like to try the DSL program also. I am very encouraged that the music problem with the Intents is fixable.
Last night, however, I went to my child’s end-of-year school band concert. I tried both music programs, and overall, found it hard to clearly hear the individual instrument sections, the way I used to be able to. I’ve been to many school band concerts with the OPNs, and I turn them down since the music is quite loud, but can still hear and enjoy the music. But last night was different. I can think of a couple other things I could have tried, with the EQ settings on each of the Custom programs, and moving volume up and down. But I won’t have an opportunity to try any of those again. I suppose I could try finding some marches to listen to and turning up the stereo very loud? All in all, I enjoyed hearing my son play but overall the experience made me sad that I couldn’t hear as well as I wanted to, as well as I could with the OPNs.