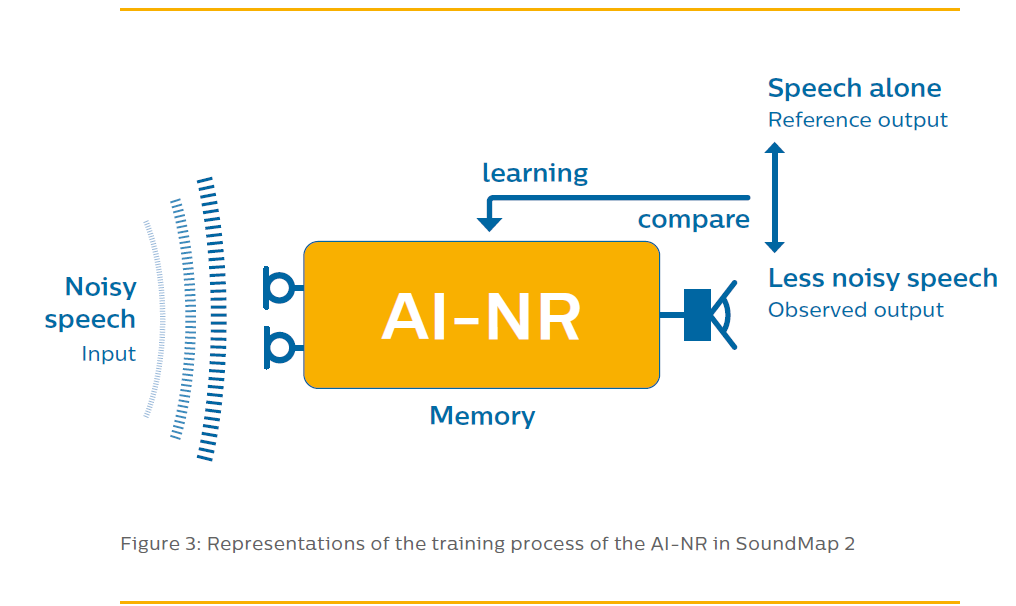
The Philips HearLink 9030 and 9040 uses AI to train itself to do better noise reduction from noisy speech. Below is an illustration of how it does that. It feeds a noisy speech input sample through the AI engine (one at a time) and observes the (cleaned up speech) output result and compare it against the same speech sample that does not have any noise in it. If the comparison is not a good match, the AI engine tweaks itself (by mathematically adjusting its coefficients inside the engine to help reduce/minimize the discrepancies) so that hopefully in the next training cycle, with another noisy speech sample set of data, it’ll do better. The training went through hundreds of thousands of these samples until the AI engine is deemed effective enough for cleaning up the noisy speech.
The Oticon More and Real uses AI as well, and particularly it uses a subset of AI called DNN (Deep Neural Network) to train itself. But instead of training itself on noisy speech samples (with clean no-noise speech samples as reference to compare against the AI engine’s outputs), the scope of the Oticon DNN is much broader. It’s not just about the noisy speech samples anymore like with the Philips HearLink, but it’s now processing a whole sound scene at a time.
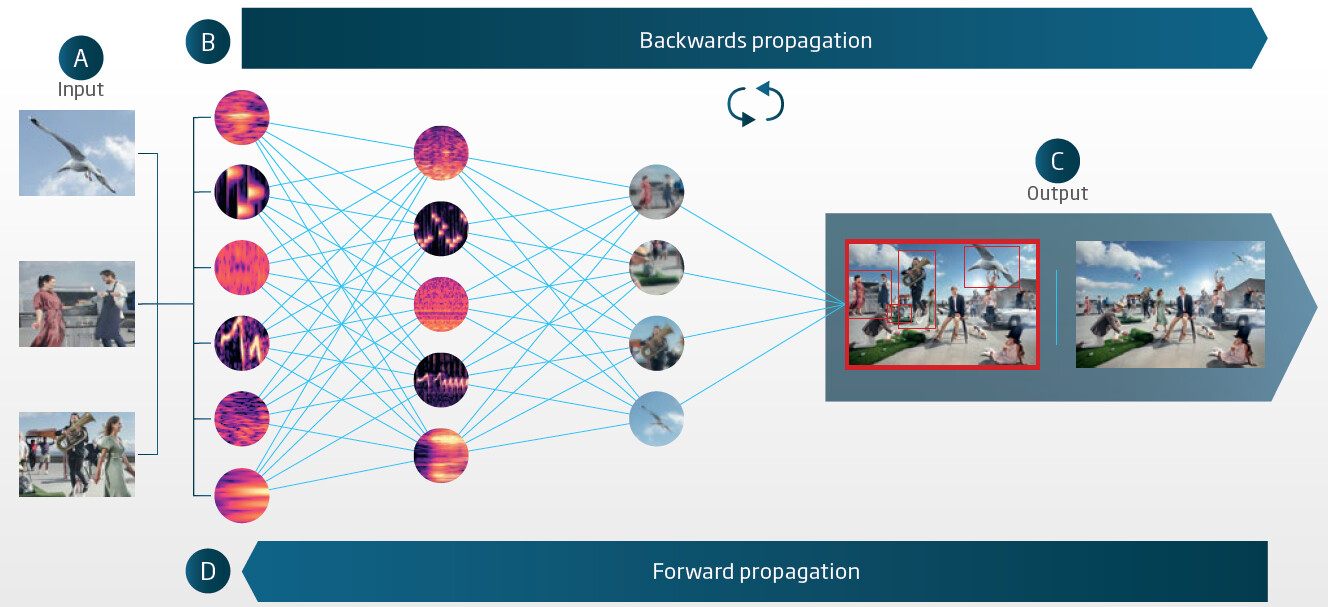
Below is an illustration of the Oticon DNN with various sound scenes as an input. Each vertical line represent a neural phase, each circle a neuron, with the first phase breaking down the sound scene into various sound components, then transform and combine these sound components into more grouping at the next level, then more grouping at the next level, and so on (not necessarily just only 3 levels as shown here for simplicity), until the whole sound scene that was originally read in get reproduced again at its output. This is the forward propagation phase. Then it compares the resulting reproduced sound scene against the original sound scene to see how well they match. If they don’t match well, it does backward propagation to tweak the relationship between each neuron (by tweaking the mathematical coefficient values representing the lines connecting circular representation here) to help minimize the discrepancies between the final output and the referenced sound scene. Then the next sound scene is pushed through the DNN and more tweaking occurs for each sound scene to make the DNN better and better (more accurate) over time as more sound scenes are used to train the DNN. In the end, a total 12 million sound scenes were used to train the Oticon DNN.
Note that both the Philips and Oticon AI training took place up front in the labs (which is a form of supervised learning). They don’t do unsupervised continuous learning with real live information presented to the real users of the aids in real time.
So the main difference here is their core AI technologies → Oticon trained their DNN at the sound scene level (using 12 million sound scenes), but Philips train their AI at the noisy speech sample level (using hundreds of thousands of speech samples). We can deduce here that Philips is particularly interested in using the AI power to focus primarily on reducing noise in speech. If this means that the surrounding sounds get removed/attenuated just to get better/clear speech, then so be it.
And indeed so, because a forum member who wore the Oticon OPN tried out the HearLink 9030, liked it a lot for its great speech in noise clarity, but then switched over to the More because he prefers and is used to the open paradigm from his OPN, because with the HearLink, he feels that he doesn’t get to hear everything he wants to hear in noisy places, although he can hear speech very well in noisy places. You can search for the Philips 9030 threads here on this forum and will find this particular one I mentioned.
Meanwhile, Oticon, with their open paradigm in mind, is not just interested in speech alone, but also interested in all the surrounding sounds as well. So Oticon basically breaks down the whole sound scene into various sound components in that scene, and chooses to balance out all the components of that sound scene so that everything can be heard, but albeit “rebalanced” to prioritize on speech and give less priority (hence more attenuation, but not totally blocked out) to sound components that may be considered noise, like car traffic on the road, waves noise in the ocean, fan noise in an AC room, babbles of speaking voices in a restaurant.
The Real has added 2 new features from the More, 1) the sudden sound stabilizer and 2) the wind & handling stabilizer. The Philips 9040 added the same 2 features from the 9030, and they call the technology containing these 2 features the SoundProtect technology. So from the peripheral technologies perspective, the Oticon and Philips aids (starting with the OPN and 9030 respectively) are very similar. Nevertheless, their core technologies are still different and not the same.